
一个项目上线了两个月,除了一些反馈的优化和小Bug之外,项目一切顺利;前期是属于推广阶段,可能使用人员没那么多,当然对于项目部署肯定提前想到并发量了,所以早就把集群安排上,而且还在测试环境搞了一下压测,绝对是没得问题的;但是,就在两个月后的一天,系统突然跑的比乌龟还慢,投诉开始就陆续反馈过来了。
经过排查,原来是频繁执行一条耗时100ms的SQL导致,100ms感觉不长,但就是把系统搞崩了,具体细节如下。
项目采用ABP进行开发,集成统一的认证中心(IDS4),部分数据对接第三方系统,拆分后的这个项目架构相对简单。
考虑并发量不高,就算是高峰期也不会超过1000,于是就搞了个单台的数据库服务器(MySQL),测试环境中经过压测,完全能抗住。
上线时,由于线上资源的关系,DB服务器的配置没有按测试环境的标准来分配,相关人员想着后续看情况进行补配。上线推的比较紧,简单评估了配置风险,初步判断没啥大问题,于是就推上线了。
相关技术栈:ABP、IdentityServer4、Autofac、AutoMapper、Quartz.NET、EF Core、Redis、MySQL等,这都不重要,重要的是100ms的SQL把系统搞崩了。
由于系统相对不大,并没有把分布式日志、调度监控,性能监控集成上去。
上线期间,前期处于使用推广阶段,一切正常。两个月后的一天,系统处于使用高峰时段,突然陆续收到反馈:系统有点卡!!!于是赶紧进行排查。
由于系统已经是集群部署的,慢这个问题首先怀疑是数据库服务器,于是让DBA的同事排查了一下,没有锁,只是有大量事务等待提交(waiting for handler commit),通过如下命令可查的:
# 查看正在执行的脚本 select * from information_schema.PROCESSLIST t where t.COMMAND != 'Sleep' order by time desc; 看到都是插入审计日志记录导致,一看日志记录频率,差不多一秒500条记录。DBA同事说可能是记录插入频繁导致,此时CPU已经爆到100%了,为了快速解决问题,于是就赶紧关掉了一些不必要的日志记录。
这么一改,稍微降了一点,没有事务提交的记录,系统勉强可以撑着用,但是CPU还是在85%~97%波动;
看到这种情况,当然还是不放心,继续排查。 中间有对服务器的配置产生过怀疑,但非常肯定的是这不是主要原因,于是和DBA的同事继续排查。
系统虽然可以正常使用,但时不时的也看看监控屏,CPU一直处于高水位状态,还是有点慌的,因为一有问题,信息和电话都要爆。
突然DBA同事发现有一个单表查询的SQL执行比较频繁,于是单独拿出来试了一下,查询时间150ms左右,这个表的数据量不大,8万左右,但没有加任何索引,因为想着数据量不大,查询时长还可接受,所以当时就没有加相关索引。
定位到这条SQL后,想到的第一步就是增加索引,在测试环境上试了一把,执行效率直接飞速提高到1ms;效果如下:

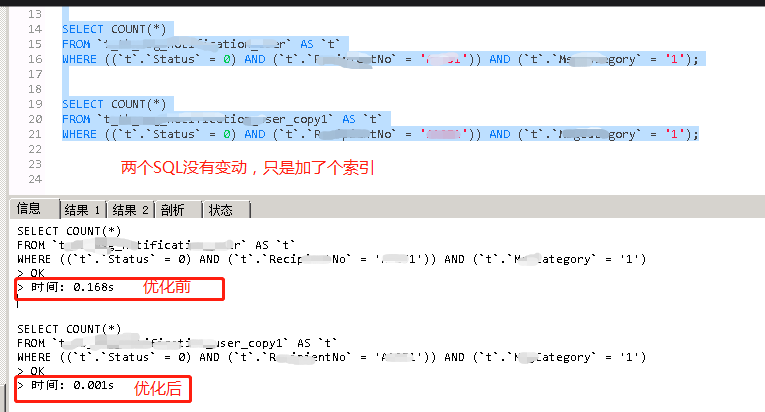
所以和DBA同事达成一致意见,在生成环境上增加复合索引(创建索引一定要注意字段顺序),在中午时候,系统使用频率不太高,于是就在生成上快速加了索引,我去,CPU一下降到了20%以内,意不意外;就算在使用高峰期,也没超过20%,通过zabbix工具监控看到CPU的效果:

问题算是解决了,总算松了一口气。
这里有个问题: CPU都爆了为什么没有报警提醒,这块DBA同事正在排查相关配置。这里发现CPU爆了,还是无意的远程到服务器,发现很卡,一看CPU才知道爆了。
系统虽小,问题不大,但其实暴露的问题还是挺多。
这次线上小事故暂时分享到这,因为项目不大,所以没有做那么多监控,但以下建议,小伙伴可以参考一下:
关注“Code综艺圈”,和我一起学习吧。

![[Blazor] 一文理清 Blazor Identity 鉴权验证](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/1.jpg&w=218&h=124&zc=1)


