
现在是互联网的世界,大家从各种网站中获取各类资源和信息,通常我们只需要牢记一个网站地址即可,至于这个网站后台的服务器在什么地方,我们并不需要关心。当我们的请求指向这个网址之后,接下来就只需要等待请求被转发到该网址的后端服务器上,得到返回的处理结果即可。
这个将网站名称解析成为服务IP地址的服务就是DNS服务,它的全称是Domain Name System,也就是域名解析服务。
那么DNS到底是怎么工作的呢?
有聪明的小伙伴可能会说了,那还不简单,搞一个统一的服务器,把世界上所有的域名对应的IP都存起来,每次需要解析的时候从这个服务去取就行了。确实,在互联网的初期就是这么干的,那时候网站还不多,域名维护的成本还不高,并且最开始还没有域名系统。
作为互联网的技术基础的ARPANET(The Advanced Research Projects Agency Network)是第一个具有分布式控制的广域分组交换网络,也是最早应用 TCP/IP 协议的网络设施。
在ARPANET网络中,每个主机都有一个数字地址,但是这个数字地址明显是反人类记忆模式的,所以科学家们希望能够给这些主机起一些好记的名字,那么就需要维护这些名字和主机之间的映射关系,在这个时候斯坦福研究所(现在被称为SRI International)接下了这个任务,他们维护了一个HOSTS.TXT 的文本文件,在这个文件中描述了主机地址和主机名字之间的映射关系。
如果有人想要更新这个HOST文件,那么需要在工作时间打电话给SRI网络信息中心,由信息中心的工作人员将主机名和地址添加到HOSTS.TXT文件中。当然这样的操作对少量的数据更新来说还可以,但是如果数据量太大的情况下就有问题了。
后面一个叫做Elizabeth Feinler的人在SRI网络信息中心的基础上搭建了WHOIS目录,用于检索有关资源、联系人和实体的信息,并且提出了域名的概念.
最开始的维护都是在一个单一的服务器上进行集中式管理,但是这种维护方式已经不能够满足日益增长的网络需求,于是在1983年Paul Mockapetris在南加州大学创建了DNS系统,并在1983年11月于RFC 882 和 RFC 883发布了相关的原始规范。
后面DNS经过一系列的发展,于1987年11月,RFC 1034和 RFC 1035取代了1983年的DNS规范。
前面我们也提过了,DNS最基本的作用就是将用户提供的域名转换成为服务器的地址。
比如我们现在有个域名叫做www.flydean.com,它对应的服务器IPv4地址是42.138.111.201,对应的IPv6地址是fe40::1024:ff:fe10:123f,DNS要做的工作就是将www.flydean.com根据需要快速的转换成为IPv4或者IPv6地址。这是DNS的第一个功能也是最重要的功能:提供域名的解析服务。
另外,在具体的应用场景中,域名背后对应的服务器IP可能是会变化的,那么就需要DNS有快速更新的功能,可以快速反映网络的变化情况,而不影响具体用户的访问。
这种操作对用用户来说是友好的,因为用户不需要知道底层服务器的变化,他们只需要知道要访问的域名即可。
最后,现代的网络应用一般都是分布式的,可能会有多个工作节点,不同的工作节点可能会被部署在不同的地方。用户在访问一个域名的时候,为了提升访问速度,应该优先访问离用户最近的那个节点。这时候DNS又承担了优化网络访问的任务,它负责向用户提供最近的服务器节点,所以在现代网络架构中,DNS的作用越来越大。
讲解完DNS的功能之后,让我们来看看DNS的组成,作为一个域名服务,DNS是由域名空间和Name servers两部分组成的。
域名空间描述的是域名的结构和命令规则,而Name servers则是对域名进行解析的服务。接下来我们分别进行讲解。
域名空间,也叫做Domain name space,它是所有域名的集合。下面是维基百科上的域名空间的示意图:

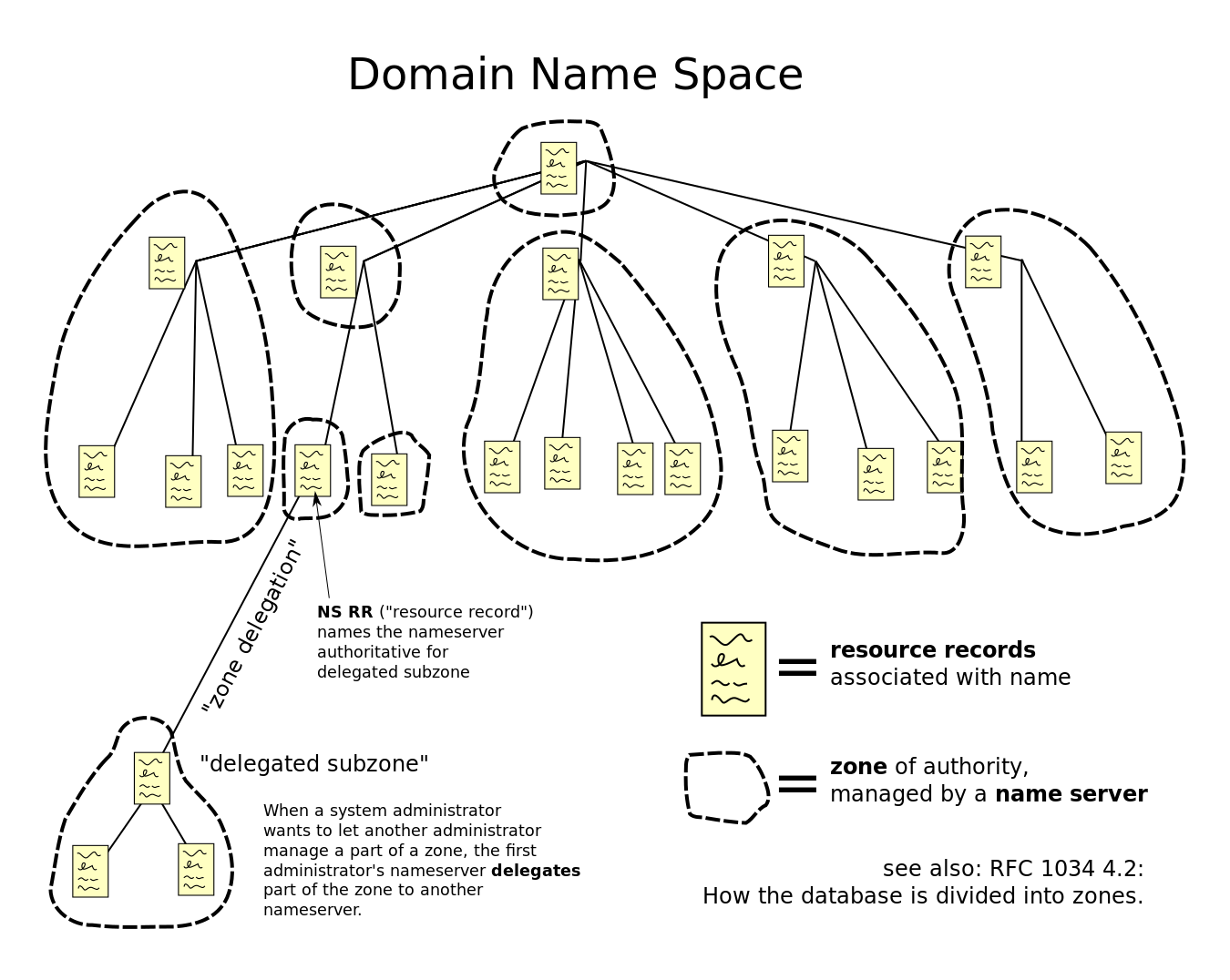
从上图可以看出,域名空间其实是一个树形结构,每个节点或者叶子节点都有一个label和RR(esource records记载着和域名相关的有用信息),域名本身由label组成,右边是其父节点的名称,用点分隔。
域名空间可以被划分为多个子空间,每个子空间可以单独进行管理,这样的子空间叫做一个域(zone)。
每个DNS域又可以被划分为一个域,也可能包含许多域和子域,具体取决于域管理器的管理选择。
大家对域名都很熟悉了,但是大家可能不是很明白域名的构成。
事实上域名是由label组成的,各个label是以点连接起来的,比如:www.flydean.com。
每个label都可以看做是域的一个层级,最右边是顶级域名com,左边的是右边域名的子域名,比如flydean是com的子域名,www是flydean.com的子域名,以此类推,总共可以有127个层级结构。
每个label可以包含0到63个字符,总共的域名长度不能超过253个字符。为什么是253个字符而不是255个字符呢?那是因为有2个字符是用来存储长度值的。
一般来说域名的标签是以ASCII字符表示的,通常使用a-z,A-Z,0-9和连字符来表示,这种规则简称为LDH(letters, digits, hyphen)规则。
在域名中,字符串是大小写不敏感的,这就意味着www.flydean.com和WWW.FLYDEAN.COM是等价的。
注意,标签不能以连字符开头或者结尾,并且顶级域名不能全为数字。
有朋友可能会问了,不对呀,为什么我听过中文域名呢?
这是因为为了解决域名只能使用ASCII编码的问题,ICANN通过了一个叫做IDNA国际化域名的系统,通过这个系统,用户应用程序(例如Web浏览器)可以使用Punycode将Unicode字符串映射到有效的DNS字符集。
什么是Punycode呢?Punycode是一种使用ASCII字符集来表示Unicode的编码方式。感兴趣的同学可以自行探索,这里就不细讲了。
name servers也被称为名称服务器,是用来解析域名的服务器。名称服务器是一种客户端-服务器的架构,每个名称服务器用于发布有关该域的信息以及管理从属于它的任何域的名称服务器。
这样的名称管理器就构成了层级结构。为了提升域名解析的效率,通常会需要使用缓存来存储域名和服务器地址的对应关系,但是有时候我们需要时效性更高的场景和服务,于是出现了一种特殊的名称服务器,这种服务器叫做权威名称服务器。
为什么叫权威名称服务器呢?这是因为权威名称服务器仅从由原始来源配置的数据中给出DNS查询的答案,而不是通过对另一个名称服务器的查询获得的结果。它是域名服务器查询中的最后一站,如果权威名称服务器中保存有请求的记录,则其会将已请求主机名的IP地址返回到发出初始请求的DNS解析器.
上面讲了那么多概念性的东西,大家可能会有些懵。 没关系,这里我们举一个具体的例子来观察一下DNS查询的整个流程。
假如用户在浏览器中输入www.flydean.com想访问这个网站,因为用户输入的是一个域名,所以需要将域名解析成为IP地址,从而发送后续的数据请求包。
因为DNS本身是一个名称服务,所以需要一个客户端来请求DNS,这个客户端就叫做DNS解析器。
一般来说DNS解析器是嵌入在浏览器中的,当用户输入URL来访问网络资源的时候,浏览器会自动调用DNS解析器去对这个URL进行解析。
那么域名解析的第一站是哪里呢?域名解析的第一站就是根服务器,也叫root服务器。
域名解析的请求由root服务器首先响应,但是root服务器并不会直接返回用户要解析的域名地址,而是根据用户访问的域名中的顶级域名的不同,返回顶级域名服务器(TLD)的地址。
比如这里我们要访问的定义域名是.com,那么root服务器会返回.com的顶级域名服务器的地址。
root服务器有多少个呢?世界上的root服务器IP地址只有13个,这是由于早期技术原因的限制导致的。这13个root服务器的IP地址中,1个为主root地址,这个地址是由ICANN负责管理的,其他12地址中9个在美国,2个在欧洲,1个在日本。
虽然root根服务器IP只有13个,但是基于这13个IP地址构建了一个服务器集群,可以有效的保证根服务器的运行稳定性。从而不至于出现根服务器不能访问导致的大规模网络错误。
回到我们的解析过程,root服务器把.com顶级域名服务器的地址返回给了DNS解析器,DNS解析会再次向.com TLD发起解析查询。
.com TLD会再次返回flydean.com的域名服务器地址给DNS解析器。
DNS解析器再次发送请求给flydean.com的域名服务器,这里的域名服务器是一个权威域名服务器,因为这里是域名解析的最后一站,存放着域名的真实IP地址,权威域名服务器经过查询得到www.flydean.com的真实IP地址,并返回给DNS解析器。
最后DNS解析器将这个IP地址返回给浏览器,供后续的浏览请求使用。
可以看到DNS解析是一个不断递归解析的过程,所以这样的解析器又被称为DNS递归解析器。
从上面的流程可以看到,每次域名的请求都需要经过root域名服务器,那么这样root域名服务器的压力会很大,为了解决这个问题,事实上我们在使用的过程中引入了DNS缓存。
缓存的目的就是将DNS数据放到离自己最近的地方,从而提示数据的处理速度和展示效率。
常见的DNS缓存有浏览器缓存和操作系统DNS缓存。
浏览器缓存就是由浏览器负责维护的DNS缓存,而操作系统DNS缓存是操作系统级的DNS缓存。
如果这两个缓存都不存在的话,那么本地的DNS客户端会将DNS查询发生到ISP(Internet 服务提供商)内部的DNS递归解析器,对于ISP来说,它也会存在DNS缓存,所以如果新增一个域名或者更改一个IP地址,并不是马上生效的,而是需要等待一定的时间来让缓存失效或者缓存刷新。
前面我们提到了DNS命名空间中每个节点都是有label和resource records (RR)组成的,RR存储着资源的描述信息,会在收到DNS查询之后返回。
DNS RR是由一条条的record构成的,下面是一条record的结构:
| 字段名 | 描述 | 长度 [octets] |
|---|---|---|
| NAME | 此记录所属的节点的名称 | 可变 |
| TYPE | RR类型 | 2 |
| CLASS | Class代码 | 2 |
| TTL | RR 保持有效的秒数 | 4 |
| RDLENGTH | RDATA 字段的长度 | 2 |
| RDATA | 附加数据字段 | 可变 |
其中NAME是树中节点的完全限定域名。
TYPE是记录类型。它表示数据的格式和用途,比如A表示用于将域名转换为IPv4地址,NS表示列出了哪些名称服务器可以响应DNS的域查找,MX表示指定用于处理指定域的邮件的邮件服务器在电子邮件地址中。
RDATA是特定类型相关的数据,例如地址记录的IP地址,或MX记录的优先级和主机名。
既然有DNS查询,那么就会有DNS查询的消息结构,DNS消息可以分为两种,分别是查询消息和回复消息。
每一个message都包含了一个消息头和四个其他部分:question, answer, authority和额外空间。
header负责控制其他的4个部分,header包含了这样几个字段: Identification, Flags, Number of questions, Number of answers, Number of authority resource records (RRs)和 Number of additional RRs, 如下表所示:
| 字段名 | 描述 | 长度[bits] |
|---|---|---|
| QR | 消息是 query (0) 还是 reply (1) | 1 |
| OPCODE | 查询的类型 QUERY (标准查询, 0), IQUERY (递归查询, 1), 或者 STATUS (服务器状态请求, 2) | 4 |
| AA | 是否是权威服务器响应 | 1 |
| TC | 表示此消息因长度过长而被截断 | 1 |
| RD | 是否递归查询 | 1 |
| RA | DNS 服务器是否支持递归 | 1 |
| Z | 保留字段 | 3 |
| RCODE | 响应码,可以是NOERROR(0),FORMERR(1,格式错误),SERVFAIL(2),NXDOMAIN(3,不存在的域名) | 4 |
整个头的标记字段长度是16bits,紧跟着4个16bits,分别表示4个其他部分的长度。
以上就是DNS的结构和DNS工作的基本流程。
本文已收录于 http://www.flydean.com/19-domain-name-service/
最通俗的解读,最深刻的干货,最简洁的教程,众多你不知道的小技巧等你来发现!
欢迎关注我的公众号:「程序那些事」,懂技术,更懂你!

![[Blazor] 一文理清 Blazor Identity 鉴权验证](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/2.jpg&w=218&h=124&zc=1)


