
由于系统版本、数据库的升级,导致测试流程阻塞,为了保证数据及系统版本的一致性,我又迫切需要想用这套环境做性能测试,所以和领导、开发请示,得到批准后,便有了这次学习的机会,所以特此来记录下整个过程。
借助工具与编码相结合形式,备份MySQL数据库,并把备份数据库还原到本地MySQL数据库,使用第三方工具完成数据迁移,代码实现SQL条数统计按照库名和表名回写结果,使用ultracompare实现比对。
Microsoft SQL Server Migration Assistant for MySQL:推荐这款工具,微软出的,但是也会有些问题,如部分表数据不能完全迁移
Navicat Premium 12:不推荐,速度慢,极容易失败
Tapdata:这款也不错,第三方工具,但不稳定,总内存溢出,底层Java写的,需要与客服沟通解决使用中问题,客服响应速度不是很理想
ultracompare:比对结果使用
Microsoft SQL Server Migration Assistant for MySQL,这款工具是微软出的,真的很好用,而且速度也算比较快。
从https://www.microsoft.com/en-us/download/details.aspx?id=54257,下载安装.
下面来介绍如何使用这款工具,具体步骤如下:
第一步:创建一个迁移工程

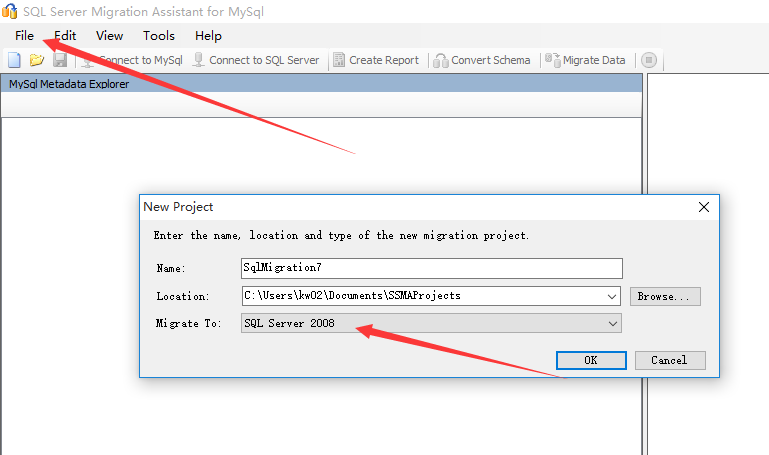
需要注意的是你需要选择迁移到的SQL Server数据库的版本,目前支持:SQL Azure,SQL Server 2005,SQL Server2008,SQL Server 2012,SQL Server2014,根据实际需要选择你要迁移到目标数据库的版本。
第二步:连接源数据库和目标数据库
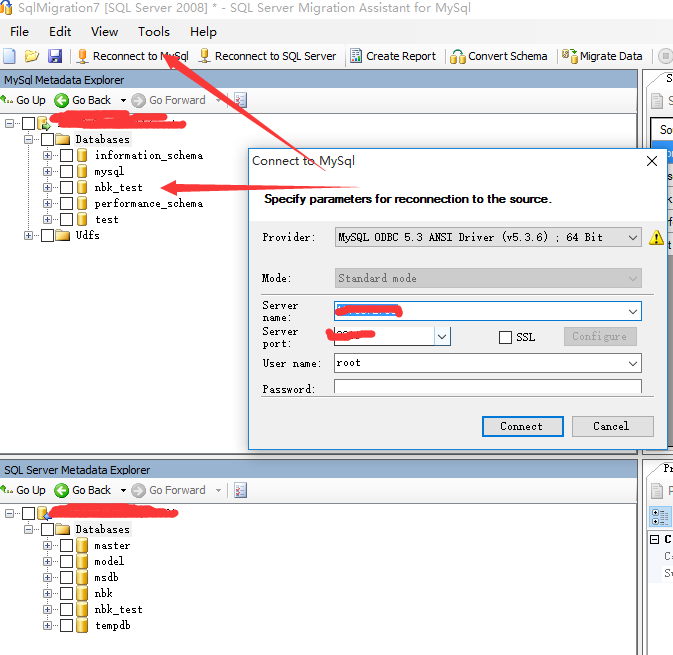
上面的是源:MySQL,下面的是目标:SQL Server
第三步:选择需要迁移的数据库创建迁移分析报告
此报告会分析当前需要迁移的数据库中的所有表结构并会生成一个可行性报告

生成的报告如下:
分析需要转换的对象,表,数据库有多少个,是否存在不可转换的对象等信息,如有检查错误会下下面输出

第四步: 转换schema 也就是数据库结构
迁移分两步:1.转换数据库结构,2.迁移数据;

第五步:在源数据库转换完schema之后记得在目标数据库上执行同步schema操作
否则转换的数据库结构是不会到目标数据库的

点击同步之后同样会有一个同步的报告:
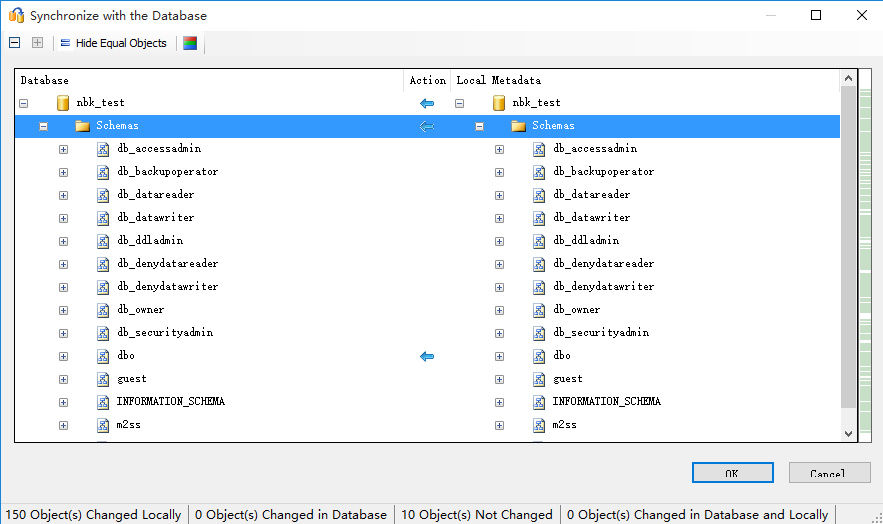
点击OK之后就真正执行同步操作会将你转换完的结构同步到目标数据库上,创建对应的表及其他对象。同步操作完成之后会有如下输出:

第六步:结构同步完成之后接下来就是数据迁移操作了
我们可以看到右边有几个tab页,当前选中的是Type Map,会列出源数据库和目标数据库的字段类型的mapping关系
因为不同数据库之间的数据类型还是有所差异的。
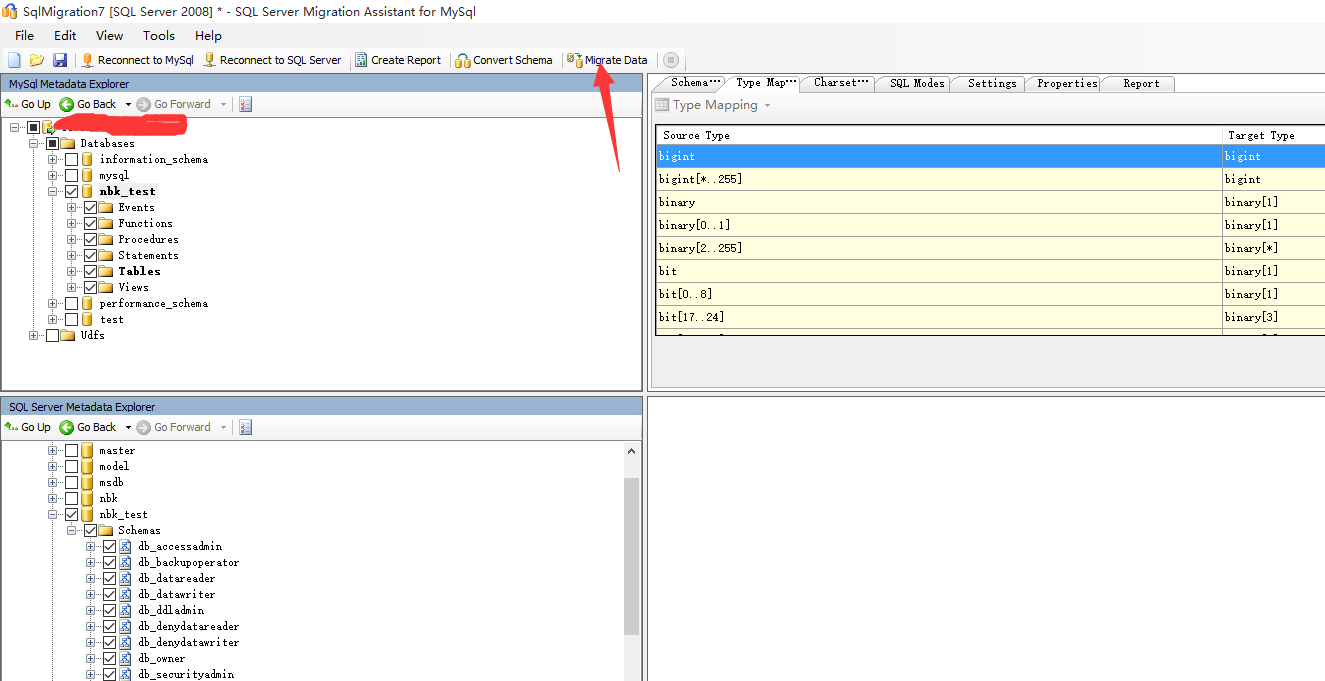
点击Migrate Data之后需要再次确认输入源数据库密码和目标数据库密码,然后开始真正的数据的迁移。

执行之后就等待完成就好,同样会生成一个数据迁移完成的报告。至此数据迁移就可以完成了。
Navicat Premium 12这款工具操作更简单,因为很多步骤可以图形化,相对简便。
具体操作步骤如下:
建立MySQL、SqlServer连接,
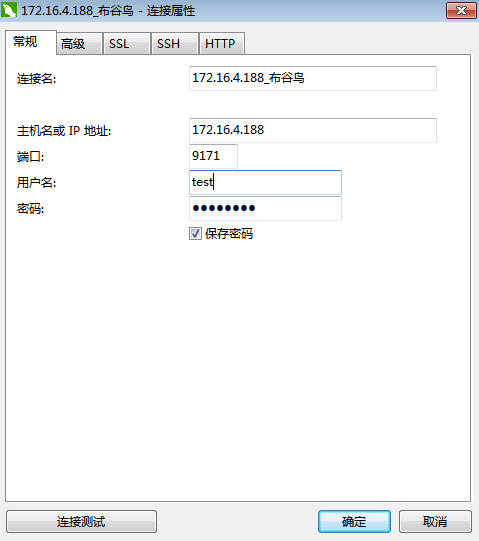
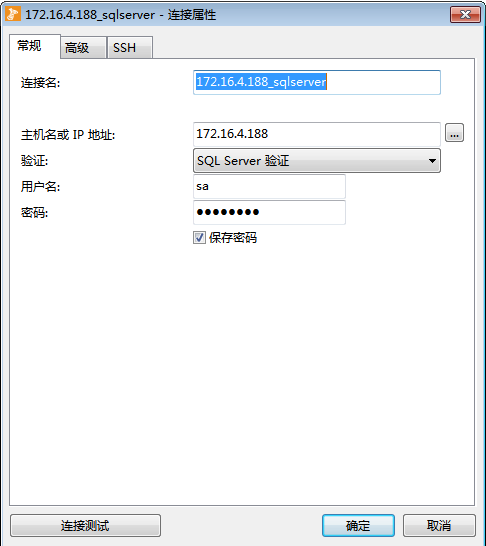
双击MySQL的连接,建立连接
然后选择navicat 的左上角工具

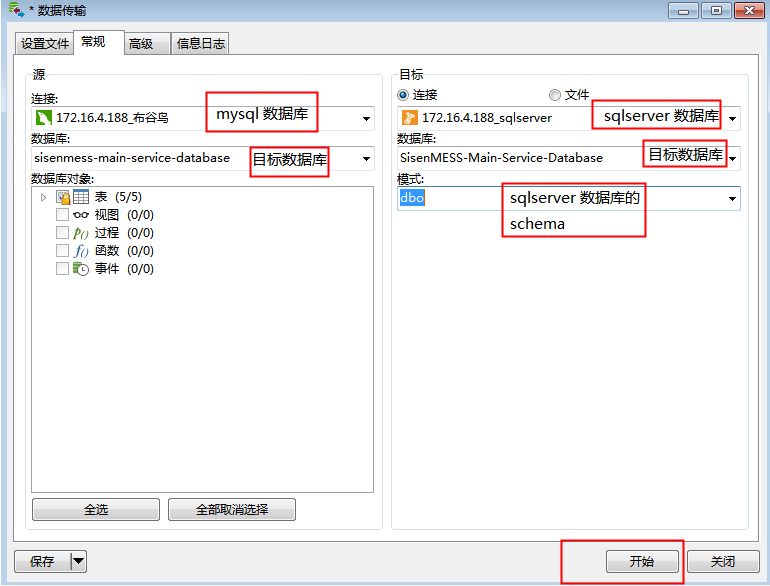
数据将自动导入
注意:该工具将不会同步约束,比如:默认值之类的。但是非空约束是可以传递到SqlServer。
Tapdata,这个工具是永久免费的,也算比较好用,具体使用方法如下:
第一步:配置MySQL 连接
1、点击 Tapdata Cloud 操作后台左侧菜单栏的【连接管理】,然后点击右侧区域【连接列表】右上角的【创建连接】按钮,打开连接类型选择页面,然后选择MySQL
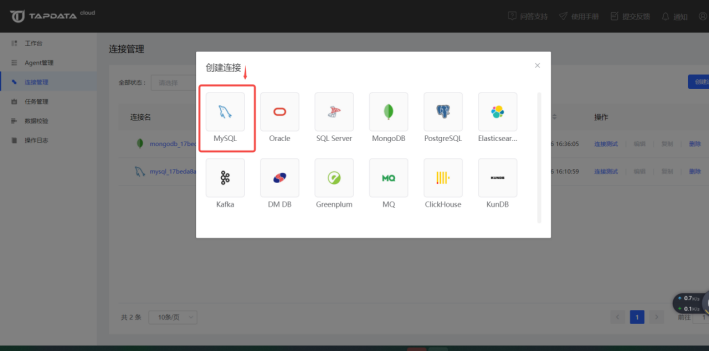
2、在打开的连接信息配置页面依次输入需要的配置信息

【连 接 名 称】:设置连接的名称,多个连接的名称不能重复
【数据库地址】:数据库 IP / Host
【端 口】:数据库端口
【数据库名称】:tapdata 数据库连接是以一个 db 为一个数据源。这里的 db 是指一个数据库实例中的 database,而不是一个 mysql 实例。
【账 号】:可以访问数据库的账号
【密 码】:数据库账号对应的密码
【时 间 时 区】:默认使用该数据库的时区;若指定时区,则使用指定后的时区设置
第二步:配置 SQL Server 连接
3、同第一步操作,点击左侧菜单栏的【连接管理】,然后点击右侧区域【连接列表】右上角的【创建连接】按钮,打开连接类型选择页面,然后选择 SQL Server

4、在打开的连接信息配置页面依次输入需要的配置信息,配置完成后测试连接保存即可。
第三步:选择同步模式-全量/增量/全+增
进入Tapdata Cloud 操作后台任务管理页面,点击添加任务按钮进入任务设置流程
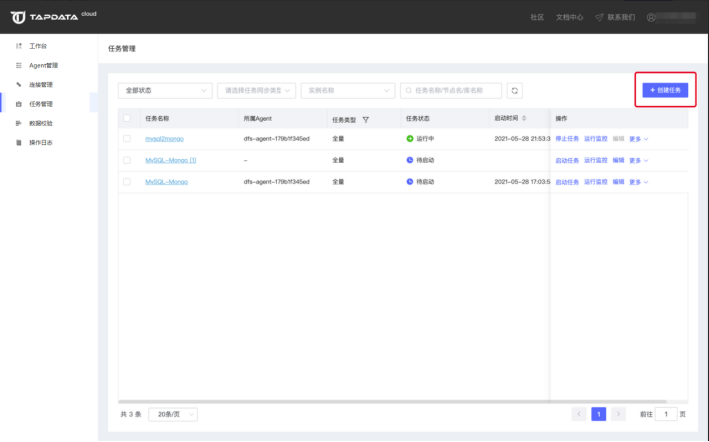
根据刚才建好的连接,选定源端与目标端。
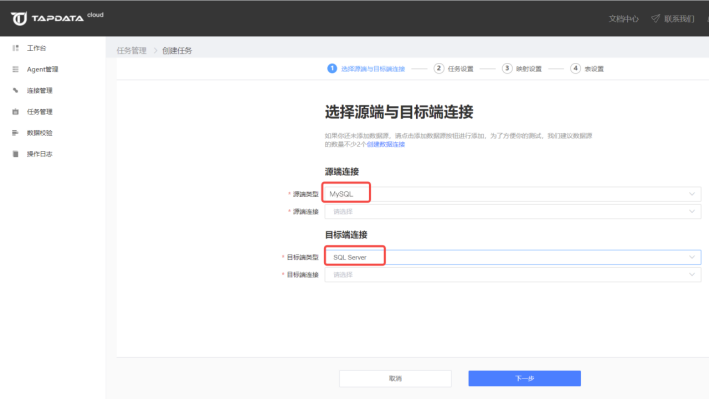
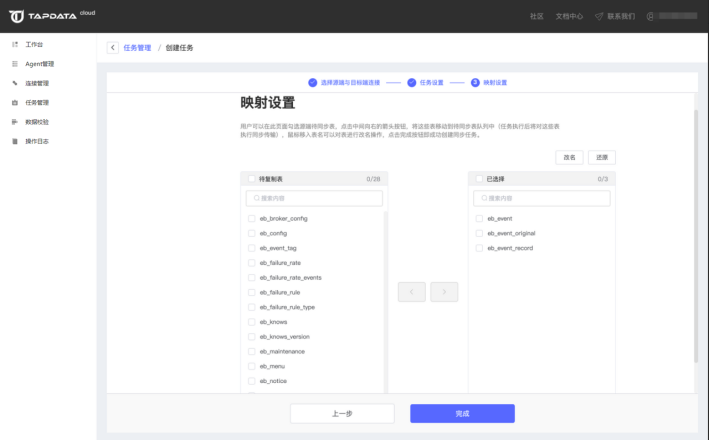
根据数据需求,选择需要同步的库、表,如果你对表名有修改需要,可以通过页面中的表名批量修改功能对目标端的表名进行批量设置。
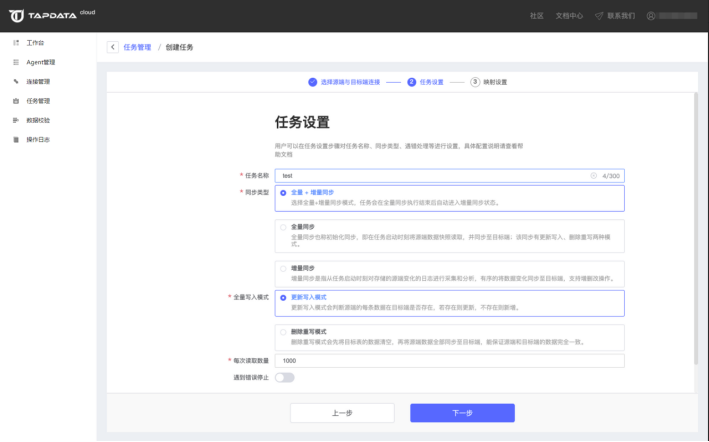
在以上选项设置完毕后,下一步选择同步类型,平台提供全量同步、增量同步、全量+增量同步,设定写入模式和读取数量。
如果选择的是全量+增量同步,在全量任务执行完毕后,Tapdata Agent 会自动进入增量同步状态。在该状态中,Tapdata Agent 会持续监听源端的数据变化(包括:写入、更新、删除),并实时的将这些数据变化写入目标端。
点击任务名称可以打开任务详情页面,可以查看任务详细信息。
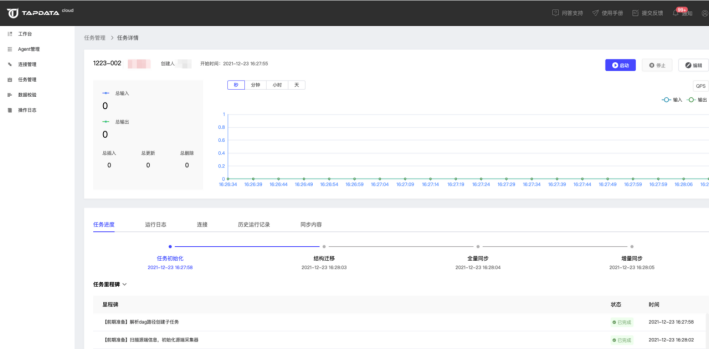
点击任务监控可以打开任务执行详情页面,可以查看任务进度/里程碑等的具体信息。

第四步:进行数据校验
一般同步完成后,我都习惯性进行一下数据校验,防止踩坑。
Tapdata 有三种校验模式,我常用最快的快速count校验 ,只需要选择到要校验的表,不用设置其他复杂的参数和条件,简单方便。

如果觉得不够用,也可以选择表全字段值校验 ,这个除了要选择待校验表外,还需要针对每一个表设置索引字段。
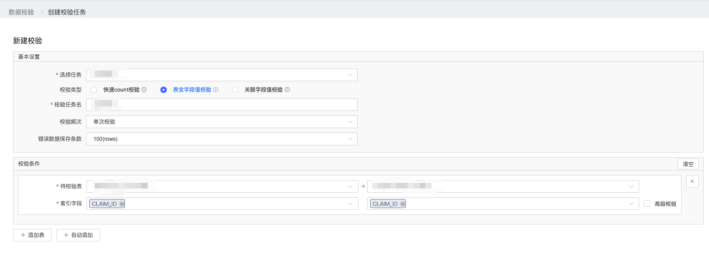
在进行表全字段值校验时,还支持进行高级校验。通过高级校验可以添加JS校验逻辑,可以对源和目标的数据进行校验。

还有一个校验方式关联字段值校验 ,创建关联字段值校验时,除了要选择待校验表外,还需要针对每一个表设置索引字段。
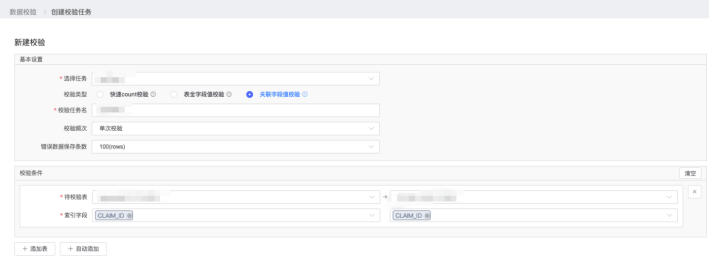
以上就是 MySQL数据实时同步到 SQL Server 的操作分享。
查询某个库的所有表名称
select table_name from information_schema.tables where table_schema='数据库名'; 查询某个数据库中所有的表名 列名 字段长度
SELECT TABLE_NAME as '表名', COLUMN_NAME as '列名',COLUMN_COMMENT,DATA_TYPE as '字段类型' ,COLUMN_TYPE as '长度加类型' FROM information_schema.`COLUMNS` where TABLE_SCHEMA='数据库名' order by TABLE_NAME,COLUMN_NAME SQLserver 查询当前库 所有表名
SELECT Name FROM SysObjects Where XType='U' ORDER BY Name; 查询数据库中重复数据按照ID查询
SELECT id FROM 数据库名 where id<>'' GROUP BY id HAVING COUNT(*)>1 删除一个表中各字段完全相同情况,只留一条数据
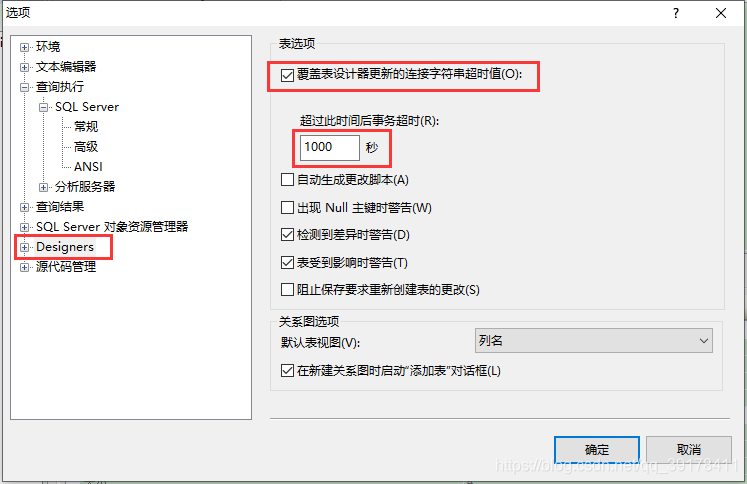
-- delete top(1) from 数据库名 where id =id值 解决sqlserver问题:超时时间已到。在操作完成之前超时时间已过或服务器未响应。
1、点开菜单栏:工具 - > 选项
2、设置脚本执行超时时间(根据自己需求,0为不限制)

3、设置链接字符串更新时间(根据自己需求,范围为1-65535)
Navicat Premium 16 无限试用
@echo off echo Delete HKEY_CURRENT_USERSoftwarePremiumSoftNavicatPremiumRegistration[version and language] for /f %%i in ('"REG QUERY "HKEY_CURRENT_USERSoftwarePremiumSoftNavicatPremium" /s | findstr /L Registration"') do ( reg delete %%i /va /f ) echo. echo Delete Info folder under HKEY_CURRENT_USERSoftwareClassesCLSID for /f %%i in ('"REG QUERY "HKEY_CURRENT_USERSoftwareClassesCLSID" /s | findstr /E Info"') do ( reg delete %%i /va /f ) echo. echo Finish pause 整个迁移过程,共耗时近两周,比我想象中的要难得多,遇到的问题也是真的很棘手,不得不说,当数据量很大时,确实会给数据的操作带来巨大挑战。

![[Blazor] 一文理清 Blazor Identity 鉴权验证](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/3.jpg&w=218&h=124&zc=1)


