
本文是关于TOWARDS EFFICIENT MODELS FOR REAL-TIME DEEP NOISE SUPPRESSION的介绍,作者是Microsoft Research的Sebastian Braun等。相关工作的上下文可以参看博文
本文设计的是基于深度学习的语音增强模型,工作的贡献点有二:
系统框图如下

要说明如下几点:
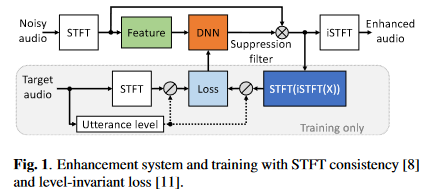
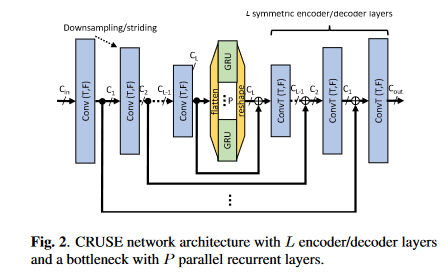
16 kHz的采样率,20 ms帧长,10 ms帧移以及320点FFT。输入特征是(Batch_size times 1 times num_frames times num_bins),卷积层通道数从16开始,依次加倍,直到倒数第二层,最后一层输出通道数则为(C_L),比如(L=4)层且(C_L=120),则卷积层的输出通道数依次为(16-32-64-120),转置卷积层的输出通道数依次为(64-32-16-1),最后一层始终为1以保证输出是幅度掩蔽。分组GRU的层数为(N)分组数为(P)。网络命名规则为(CRUSEL-C_L-N times RNNP)
数据集的增广方法可以参考博文
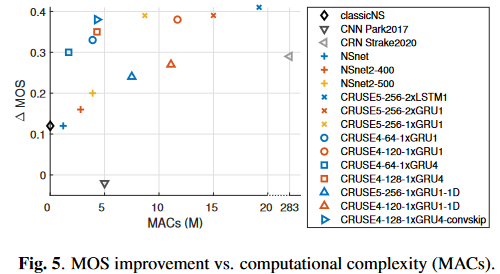
评估指标是用于评价语音质量的DNSMOS(P.808)和用于评估计算量的MACs,需要注意的是这里的DNSMOS(P.808)应该是与目前(2022/04/24)可用的DNSMOS(P.808&P.835)中的P.808的分数有差异了
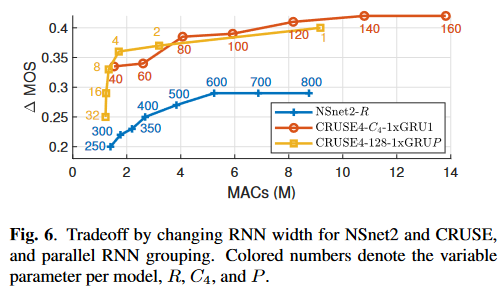
(图中横轴是MACs,纵轴是(Delta)MOS,因此在图中偏左上的方法更优)
分析结论:
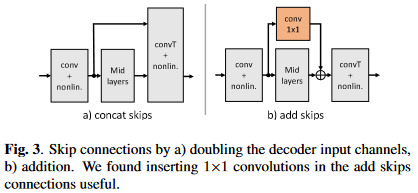
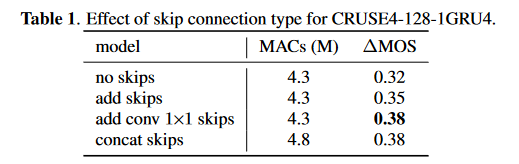
最后是一个消融实验证明设计的跳转连接的有效性

![[Blazor] 一文理清 Blazor Identity 鉴权验证](http://www.itfaba.com/wp-content/themes/kemi/timthumb.php?src=http://www.itfaba.com/wp-content/themes/kemi/img/random/3.jpg&w=218&h=124&zc=1)

