
在做了几年前端之后,发现互联网行情比想象的差,不如赶紧学点后端知识,被裁之后也可接个私活不至于饿死。学习两周Go,如盲人摸象般不知重点,那么重点谁知道呢?肯定是使用Go的后端工程师,那便利用业余时间找了几个老哥对练一下。其中一位问道在利用多个goroutine发送请求拿到结果之后如果进行销毁。是个好问题,研究了一下需要利用Context,而我一向喜欢研究源码,继续深挖发现细节非常多,于是乎有此这篇文章。


type Value struct { v interface{} }
type ifaceWords struct { typ unsafe.Pointer data unsafe.Pointer }
bytes := []byte{104, 101, 108, 108, 111} p := unsafe.Pointer(&bytes) //强制转换成unsafe.Pointer,编译器不会报错 str := *(*string)(p) //然后强制转换成string类型的指针,再将这个指针的值当做string类型取出来 fmt.Println(str) //输出 "hello"
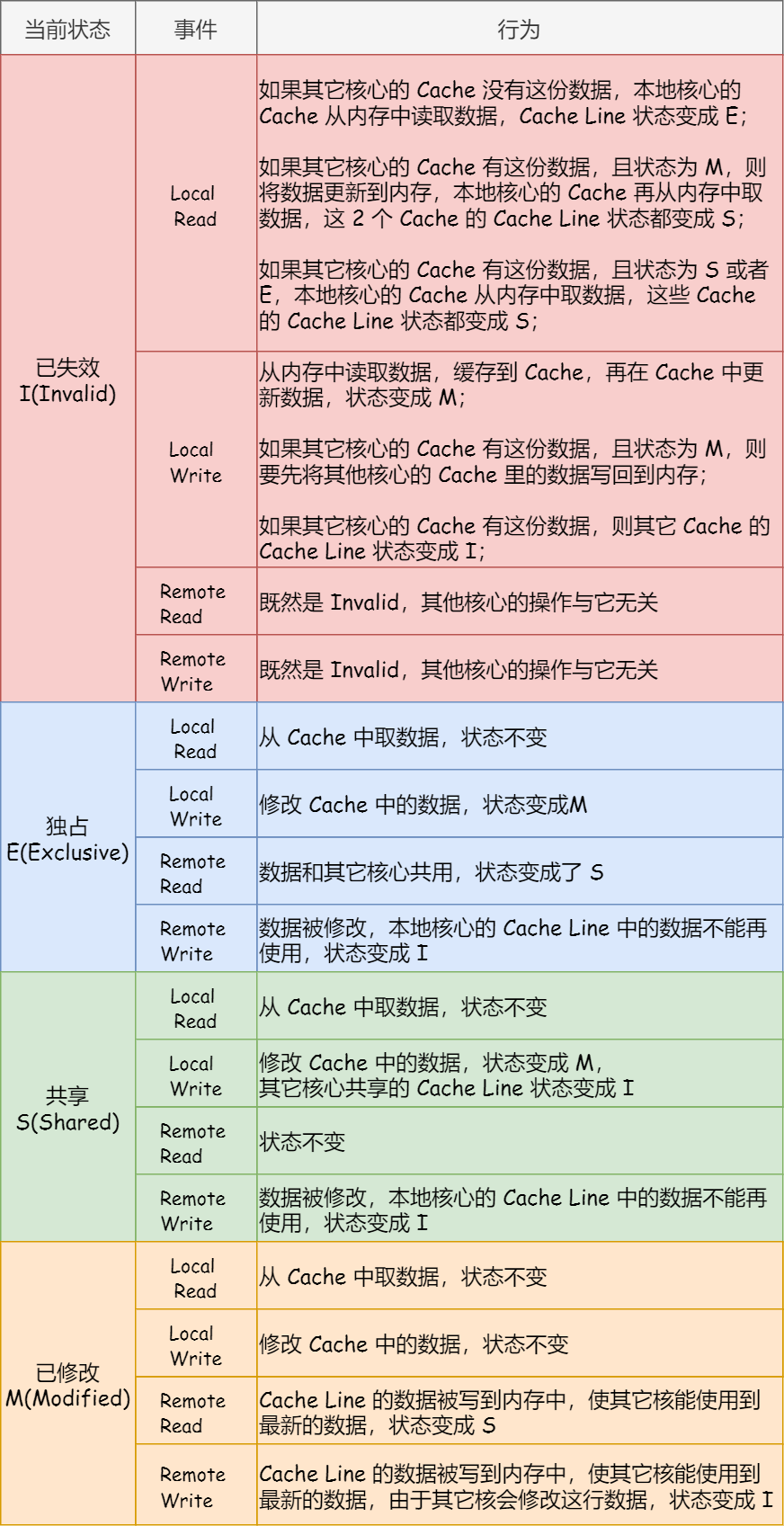
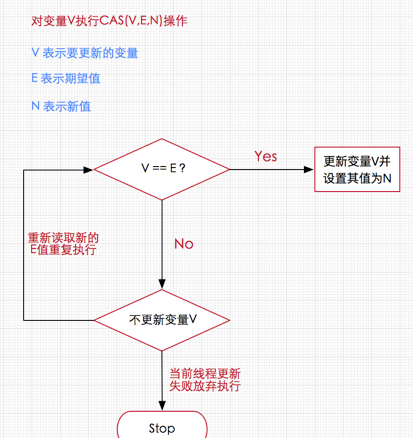
func (v *Value) Store(x interface{}) { if x == nil { panic("sync/atomic: store of nil value into Value") } // 通过unsafe.Pointer将现有的和要写入的值分别转成ifaceWords类型, // 这样我们下一步就可以得到这两个interface{}的原始类型(typ)和真正的值(data) vp := (*ifaceWords)(unsafe.Pointer(v)) // Old value xp := (*ifaceWords)(unsafe.Pointer(&x)) // New value // 这里开始利用CAS来自旋了 for { // 通过LoadPointer这个原子操作拿到当前Value中存储的类型 typ := LoadPointer(&vp.typ) if typ == nil { // typ为nil代表Value实例被初始化,还没有被写入数据,则进行初始写入; // 初始写入需要确定typ和data两个值,非初始写入只需要更改data // Attempt to start first store. // Disable preemption so that other goroutines can use // active spin wait to wait for completion; and so that // GC does not see the fake type accidentally. // 获取runtime总当前P(调度器)并设置禁止抢占,使得goroutine执行当前逻辑不被打断以便尽快完成,同时这时候也不会发生GC // pin函数会将当前 goroutine绑定的P, 禁止抢占(preemption) 并从 poolLocal 池中返回 P 对应的 poolLocal runtime_procPin() // 使用CAS操作,先尝试将typ设置为^uintptr(0)这个中间状态。 // 如果失败,则证明已经有别的线程抢先完成了赋值操作,那它就解除抢占锁,然后重新回到 for 循环第一步进行自旋 // 回到第一步后,则进入到if uintptr(typ) == ^uintptr(0)这个逻辑判断和后面的设置StorePointer(&vp.data, xp.data) if !CompareAndSwapPointer(&vp.typ, nil, unsafe.Pointer(^uintptr(0))) { // 设置成功则将P恢复原样 runtime_procUnpin() continue } // Complete first store. // 这里先写data字段在写typ字段,因为这个两个单独都是原子的 // 但是两个原子放在一起未必是原子操作,所以先写data字段,typ用来做判断 StorePointer(&vp.data, xp.data) StorePointer(&vp.typ, xp.typ) runtime_procUnpin() return } if uintptr(typ) == ^uintptr(0) { // 这个时候typ不为nil,但可能为^uintptr(0),代表当前有一个goroutine正在写入,还没写完 // 我们先不做处理,保证那个写入线程操作的原子性 // First store in progress. Wait. // Since we disable preemption around the first store, // we can wait with active spinning. continue } // First store completed. Check type and overwrite data. if typ != xp.typ { // atomic.Value第一确定类型之后,后续都不能改变 panic("sync/atomic: store of inconsistently typed value into Value") } // 非第一次写入,则利用StorePointer这个原子操作直接写入。 StorePointer(&vp.data, xp.data) return } }
func (v *Value) Load() (x interface{}) { vp := (*ifaceWords)(unsafe.Pointer(v)) typ := LoadPointer(&vp.typ) // 原子性读 // 如果当前的typ是 nil 或者^uintptr(0),那就证明第一次写入还没有开始,或者还没完成,那就直接返回 nil (不对外暴露中间状态)。 if typ == nil || uintptr(typ) == ^uintptr(0) { // First store not yet completed. return nil } // 否则,根据当前看到的typ和data构造出一个新的interface{}返回出去 data := LoadPointer(&vp.data) xp := (*ifaceWords)(unsafe.Pointer(&x)) xp.typ = typ xp.data = data return }
/**@param delta the value to add * @return the previous value */ * Atomically adds the given value to the current value. * * public final int getAndAdd(int delta) { for (;;) { int current = get(); int next = current + delta; if (compareAndSet(current, next)) return current; } } /**@code ==} the expected value. * * @param expect the expected value * @param update the new value * @return true if successful. False return indicates that * the actual value was not equal to the expected value. */ * Atomically sets the value to the given updated value * if the current value { public final boolean compareAndSet(int expect, int update) { return unsafe.compareAndSwapInt(this, valueOffset, expect, update); }





