
MySQL 回表
五花马,千金裘,呼儿将出换美酒,与尔同销万古愁。
回表,顾名思义就是回到表中,也就是先通过普通索引扫描出数据所在的行,再通过行主键ID 取出索引中未包含的数据。所以回表的产生也是需要一定条件的,如果一次索引查询就能获得所有的select 记录就不需要回表,如果select 所需获得列中有其他的非索引列,就会发生回表动作。即基于非主键索引的查询需要多扫描一棵索引树。
要弄明白回表,首先得了解 InnoDB 两大索引,即聚集索引 (clustered index)和普通索引(secondary index)。
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有且只有一个聚集索引。
普通索引也叫二级索引,除聚簇索引外的索引都是普通索引,即非聚簇索引。
InnoDB的普通索引叶子节点存储的是主键(聚簇索引)的值,而MyISAM的普通索引存储的是记录指针。
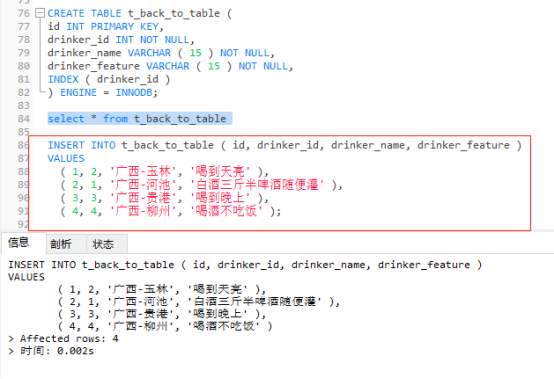
先创建一张表 t_back_to_table ,表中id 为主键索引即聚簇索引,drinker_id为普通索引。
CREATE TABLE t_back_to_table ( id INT PRIMARY KEY, drinker_id INT NOT NULL, drinker_name VARCHAR ( 15 ) NOT NULL, drinker_feature VARCHAR ( 15 ) NOT NULL, INDEX ( drinker_id ) ) ENGINE = INNODB;
再执行下面的 SQL 语句,插入四条测试数据。
INSERT INTO t_back_to_table ( id, drinker_id, drinker_name, drinker_feature ) VALUES ( 1, 2, '广西-玉林', '喝到天亮' ), ( 2, 1, '广西-河池', '白酒三斤半啤酒随便灌' ), ( 3, 3, '广西-贵港', '喝到晚上' ), ( 4, 4, '广西-柳州', '喝酒不吃饭' );

使用主键索引id,查询出id 为 3 的数据。
EXPLAIN SELECT * FROM t_back_to_table WHERE id = 3;
执行 EXPLAIN SELECT * FROM t_back_to_table WHERE id = 3,这条 SQL 语句就不需要回表。
因为是根据主键的查询方式,则只需要搜索 ID 这棵 B+ 树,树上的叶子节点存储了行记录,根据这个唯一的索引,MySQL 就能确定搜索的记录。
使用 drinker_id 这个索引来查询 drinker_id = 3 的记录时就会涉及到回表。
SELECT * FROM t_back_to_table WHERE drinker_id = 3;
因为通过 drinker_id 这个普通索引查询方式,则需要先搜索 drinker_id 索引树(该索引树上记录着主键ID的值),然后得到主键 ID 的值为 3,再到 ID 索引树搜索一次。这个过程虽然用了索引,但实际上底层进行了两次索引查询,这个过程就称为回表。
回表小结
InnoDB 引擎的聚集索引和普通索引都是B+Tree 存储结构,只有叶子节点存储数据。
id 是主键,所以是聚簇索引,其叶子节点存储的是对应行记录的数据。
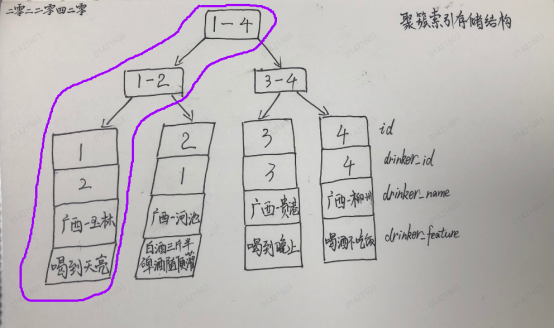
聚簇索引存储结构
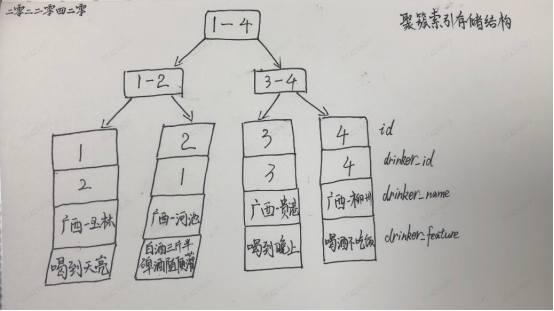
如果查询条件为主键(聚簇索引),则只需扫描一次B+树即可通过聚簇索引定位到要查找的行记录数据。
如:
SELECT * FROM t_back_to_table WHERE id = 1;
查找过程:
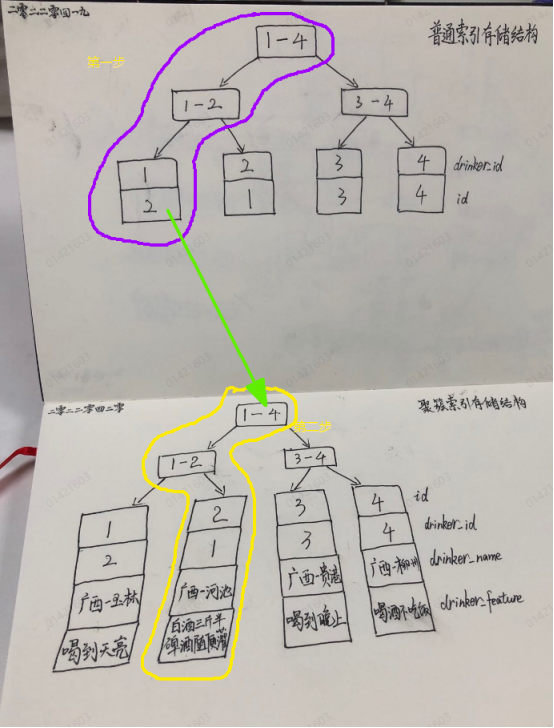
drinker_id 是普通索引(二级索引),非聚簇索引的叶子节点存储的是聚簇索引的值,即主键ID的值。
普通索引存储结构
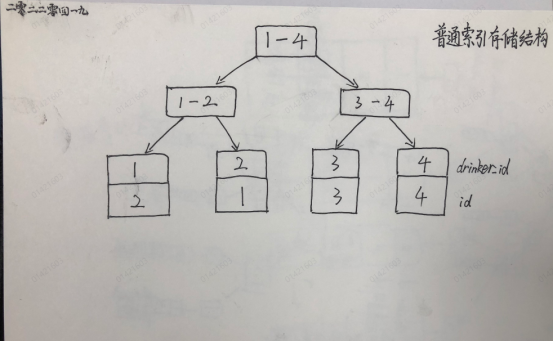
如果查询条件为普通索引(非聚簇索引),需要扫描两次B+树。
如:
SELECT * FROM t_back_to_table WHERE drinker_id = 1;
(1)第一步,先通过普通索引定位到主键值id=1;
(2)第二步,回表查询,再通过定位到的主键值即聚集索引定位到行记录数据。
普通索引查找过程
既然我们知道了有回表这么回事,肯定就要尽可能去防微杜渐。最常见的防止回表手段就是索引覆盖,通过索引打败索引。
为什么可以使用索引打败索引防止回表呢?因为其只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表查询。
例如:SELECT * FROM t_back_to_table WHERE drinker_id = 1;
如何实现覆盖索引?
常见的方法是将被查询的字段,建立到联合索引中。
解释性SQL的explain的输出结果Extra字段为Using index时表示触发了索引覆盖。
No覆盖索引case1
继续使用之前创建的 t_back_to_table 表,通过普通索引drinker_id 查询id 和 drinker_id 列。
EXPLAIN SELECT id, drinker_id FROM t_back_to_table WHERE drinker_id = 1;
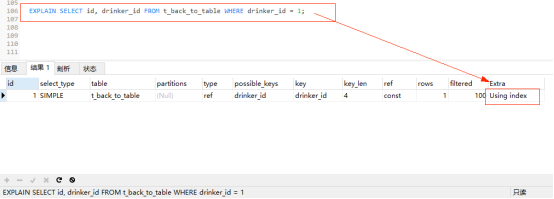
explain分析:为什么没有创建覆盖索引Extra字段仍为Using index,因为drinker_id是普通索引,使用到了drinker_id索引,在上面有提到普通索引的叶子节点保存了聚簇索引的值,所以通过一次扫描B+树即可查询到相应的结果,这样就实现了隐形的覆盖索引,即没有人为的建立联合索引。(drinker_id索引上包含了主键索引的值)
No覆盖索引case2
继续使用之前创建的 t_back_to_table 表,通过普通索引drinker_id查询 id、drinker_id和drinker_feature三列数据。
EXPLAIN SELECT id, drinker_id, drinker_feature FROM t_back_to_table WHERE drinker_id = 1;
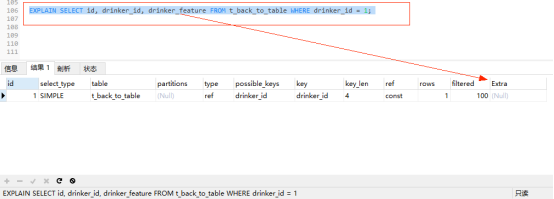
explain分析:drinker_id是普通索引其叶子节点上仅包含主键索引的值,而 drinker_feature 列并不在索引树上,所以通过drinker_id 索引在查询到id和drinker_id的值后,需要根据主键id 进行回表查询,得到 drinker_feature 的值。此时的Extra列的NULL表示进行了回表查询。
覆盖索引case
为了实现索引覆盖,需要建组合索引 idx_drinker_id_drinker_feature(drinker_id,drinker_feature)
#删除索引 drinker_id DROP INDEX drinker_id ON t_back_to_table; #建立组合索引 CREATE INDEX idx_drinker_id_drinker_feature on t_back_to_table(`drinker_id`,`drinker_feature`);
继续使用之前创建的 t_back_to_table 表,通过覆盖索引 idx_drinker_id_drinker_feature 查询 id、drinker_id和drinker_feature三列数据。
EXPLAIN SELECT id, drinker_id, drinker_feature FROM t_back_to_table WHERE drinker_id = 1;
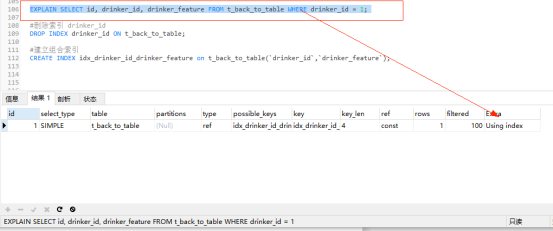
explain分析:此时字段drinker_id和drinker_feature是组合索引idx_drinker_id_drinker_feature,查询的字段id、drinker_id和drinker_feature的值刚刚都在索引树上,只需扫描一次组合索引B+树即可,这就是实现了索引覆盖,此时的Extra字段为Using index表示使用了索引覆盖。
适合使用索引覆盖来优化SQL的场景如全表count查询、列查询回表和分页查询等。
#首先删除 t_back_to_table 表中的组合索引 DROP INDEX idx_drinker_id_drinker_feature ON t_back_to_table; EXPLAIN SELECT COUNT(drinker_id) FROM t_back_to_table
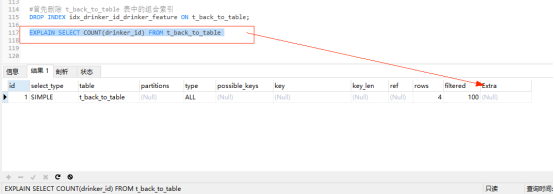
explain分析:此时的Extra字段为Null 表示没有使用索引覆盖。
使用索引覆盖优化,创建drinker_id字段索引。
#创建 drinker_id 字段索引 CREATE INDEX idx_drinker_id on t_back_to_table(drinker_id); EXPLAIN SELECT COUNT(drinker_id) FROM t_back_to_table
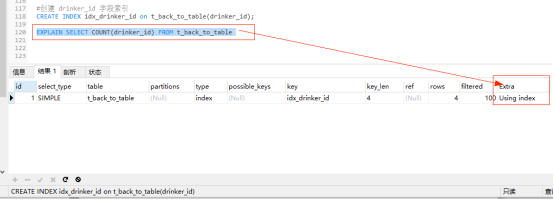
explain分析:此时的Extra字段为Using index表示使用了索引覆盖。
前文在描述索引覆盖使用的例子就是列查询回表优化。
例如:
SELECT id, drinker_id, drinker_feature FROM t_back_to_table WHERE drinker_id = 1;
使用索引覆盖:建组合索引 idx_drinker_id_drinker_feature on t_back_to_table(`drinker_id`,`drinker_feature`)即可。
#首先删除 t_back_to_table 表中的索引 idx_drinker_id DROP INDEX idx_drinker_id ON t_back_to_table; EXPLAIN SELECT id, drinker_id, drinker_name, drinker_feature FROM t_back_to_table ORDER BY drinker_id limit 200, 10;
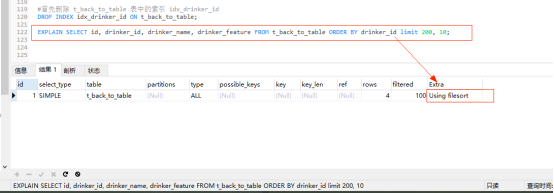
explain分析:因为 drinker_id 字段不是索引,所以在分页查询需要进行回表查询,此时Extra为U sing filesort 文件排序,查询性能低下。
使用索引覆盖:建组合索引 idx_drinker_id_drinker_name_drinker_feature
#建立组合索引 idx_drinker_id_drinker_name_drinker_feature (`drinker_id`,`drinker_name`,`drinker_feature`) CREATE INDEX idx_drinker_id_drinker_name_drinker_feature on t_back_to_table(`drinker_id`,`drinker_name`,`drinker_feature`);
再次根据 drinker_id 分页查询:
EXPLAIN SELECT id, drinker_id, drinker_name, drinker_feature FROM t_back_to_table ORDER BY drinker_id limit 200, 10;
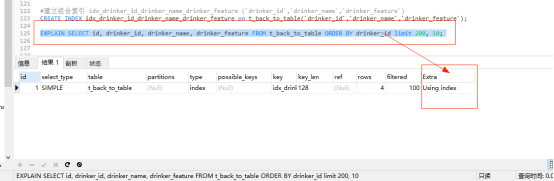
explain分析:此时的Extra字段为Using index表示使用了索引覆盖。




