
面向失败编程是编程中最难的事情。
话说程序员小林的某一天:起床->吃饭->坐地铁->到公司->敲代码->回家->玩游戏->睡觉。
这一天的另一个版本:起床->吃饭->坐地铁->到公司->突然要 24 小时健康码->进不了公司->坐地铁回去->地铁停运了->上厕所->踩到屎滑倒->摔成脑震荡。
第二个版本充满意外,貌似有些极端,但你我天天在新闻上看到类似的事情,说明它其实每天都在发生。
程序也是如此。
程序员小林给公司开发的某个系统,用户量暴涨;三年后公司上市了,小林喜迎白富美。
另一个版本:上线后第二天被 SQL 注入删库了,造成大量投诉;小林被老板痛骂一顿后,卷铺盖走人了。
程序的世界充满意外,你我的每一行代码几乎都是 bug。
写出可用的系统很容易,但写出健壮的系统很难。
我们通过储值卡消费这个例子来看看如此”简单“的案例到底存在多少让人眼花缭乱的失败场景。
假设我们给某个加油站开发个储值卡系统,用户可以往里面充钱,可以用储值卡加油消费,类似你在理发店、洗脚店开的那种充值卡。
我们看看车主加油消费的场景——而且只看这个场景中的”储值卡扣款“这一个结点。
正常流程(简化版)大致是这样的:

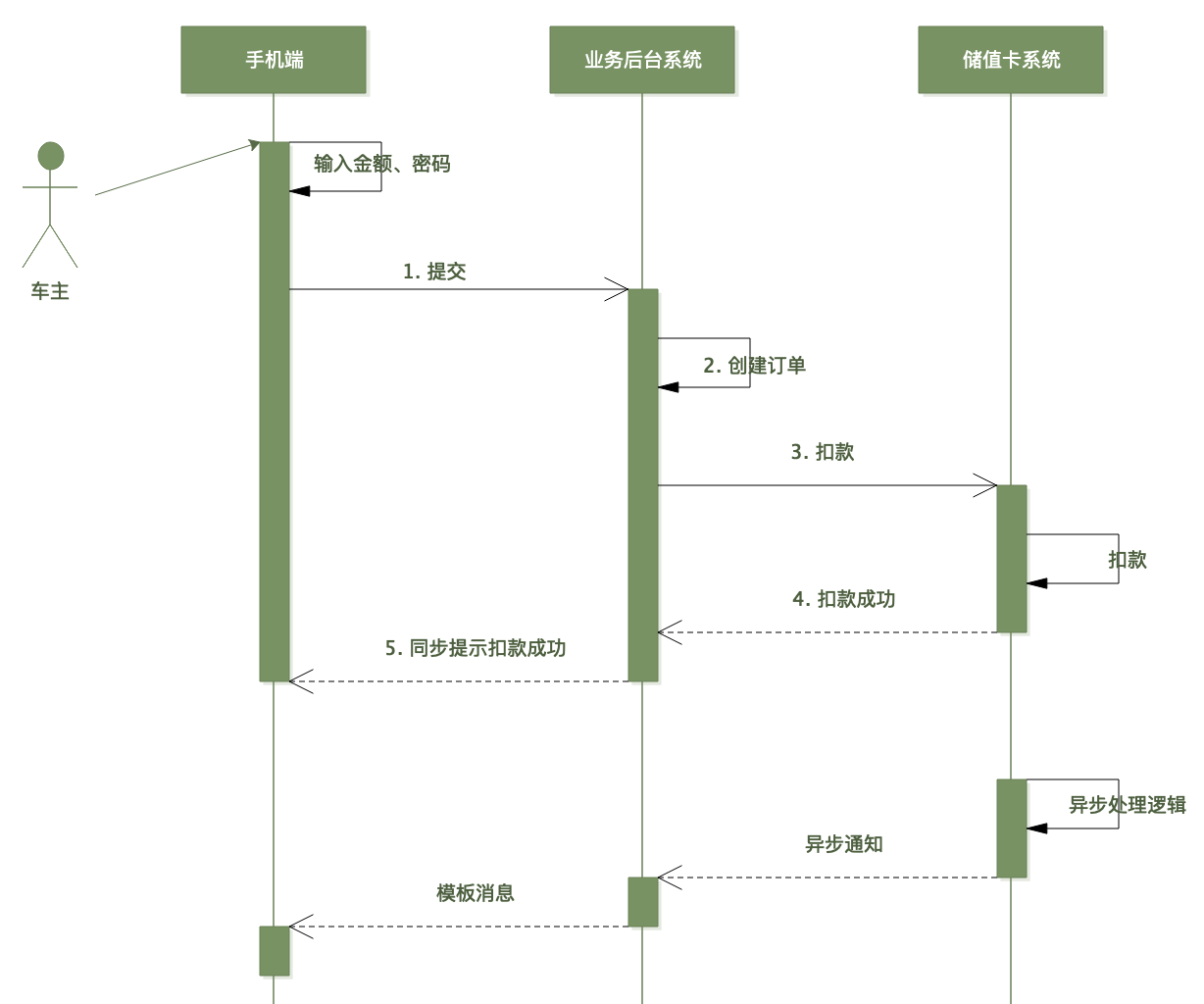
流程很简单,加油员加完油后,用户掏出手机扫码进入付款页面,输入油枪、金额,选储值卡支付,输完密码后点提交;后端创建订单后调卡服务的扣款接口执行扣款(传入卡号、订单号、金额);卡服务扣款成功后返回告知用户付款成功。
”这个需求大概要几天开发?“产品经理问小林。
”五天。“小林觉得五天绰绰有余。
”三天吧,这周我们就要上线。“
”那就三天。“小林觉得其实三天足够——不就一两个接口调用嘛,卡服务是现成的。
于是小林撸起袖子开始敲代码。进展比预想得要顺利,两天就敲完了(多少加了点班),一天测试完成,第四天就上线了!
某天夜里,小林正在撸猫时,运营同学打来电话:某车主的卡被莫名其妙扣款了!
事情是这样的:车主鲁某加了 3000 元的油,选择用储值卡支付,结果系统提示扣款失败,于是鲁某换微信付款成功,开车走人了。
蹊跷的是:鲁某十分钟后收到消息说卡扣掉了 3000 元!
明明说支付失败,怎么扣了 3000?于是鲁某打电话找油站闹。
小林赶紧排查日志,发现上图中地第 3 步(调卡服务的扣款接口)超时了,于是业务系统告知前端扣款失败。
调卡服务扣款接口超时,业务系统能直接返回失败给前端吗?
不能!
因为接口超时并不能说明卡服务那边实际上到底有没有扣成功(有可能卡服务处理成功了,但返回的时候网络出问题;也有可能卡系统负载高,业务系统等待超时从而断开连接)。
我们看看上面的异常是怎么发生的:
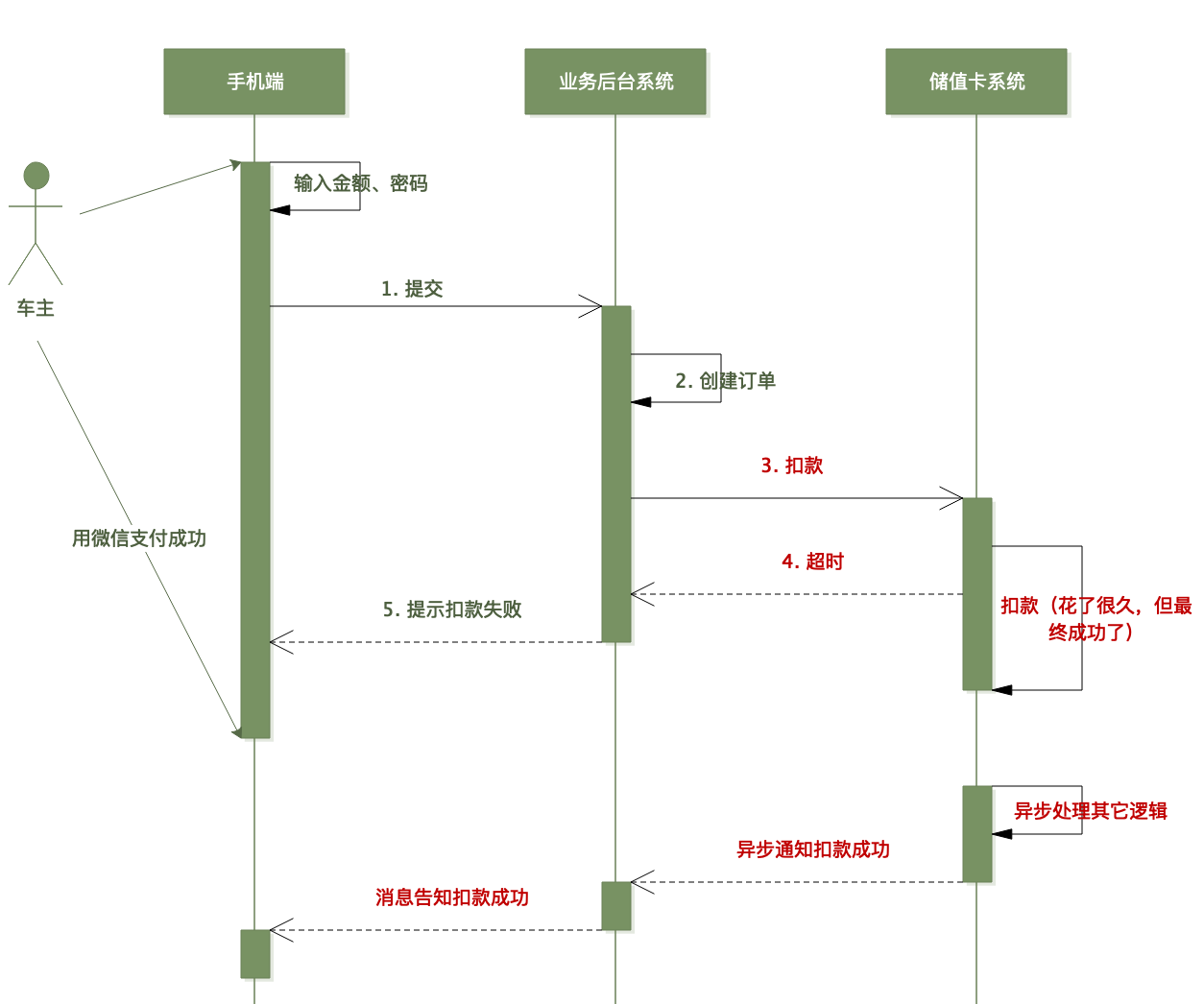
第四步超时后,业务后台直接告知车主支付失败,但实际上卡系统仍然在扣款!
那怎么办?告诉车主”请您稍后查看支付结果?“
怎么可能!
一个想法是超时后业务系统调卡服务的查询接口,看看这笔订单实际是否支付成功。
问题是,如果查询接口调用也超时呢(卡系统负载高的情况下这个概率很大)?
另外,查询接口返回没有扣款成功就能直接告诉用户扣款失败吗?
不能!
因为查询接口查数据库的时候,数据库里面没有记录,但有可能前面发起的那个扣款逻辑仍然在执行,稍后仍然会发生扣款。
既然怕查询的时候扣款逻辑仍然在执行,那我们能不能等一会(比如五分钟)再查结果呢(等那个可能的扣款执行流跑完)?
也不能!
因为车主在那等着呢!难道手机上一直在那转圈,跟车主说现在负载高,请先喝杯茶,让子弹飞一会?
因为必须要立即告知用户处理结果,所以这种情况下(扣款超时且未查到扣款记录)只能告诉用户扣款失败。
只不过,在告知用户之前,业务系统需要先撤销本次扣款申请,告诉储值卡系统本次扣款流程不能执行了(回滚本次事务)。
于是小林做了如下优化:
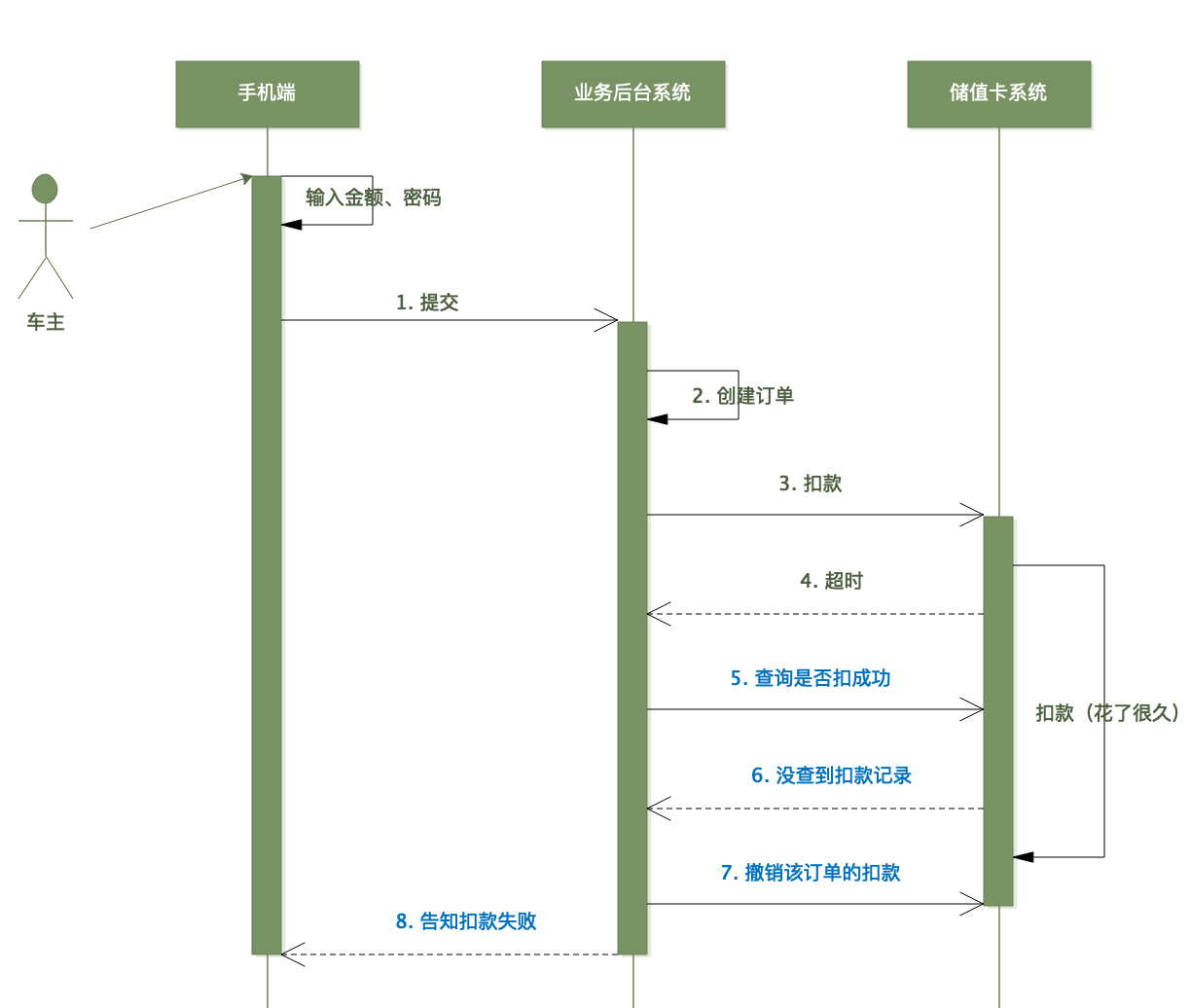
现在系统健壮多了,很久没出现上次的问题了,小林又跑去撸猫了。
某天深夜,小林又接到运营同学电话:上次的问题重现了!
尼玛,见鬼了!
小林又跑去查日志,发现确实是扣款接口超时了,但撤销接口调成功了(虽然调了几次才成功)——那为毛还扣了钱啊?
想了半天,小林终于发现了问题:和前面提到的查询问题一样,撤销的时候同样无法保证那个该死的扣款流程已经跑完了啊!这次是因为撤销逻辑确实执行了,但执行的时候扣款逻辑还在跑(还没写库)!
所以撤销接口必须考虑两种情况:
于是小林就想:既然扣款超时后立即调撤销接口有可能因时序问题导致撤销失败,那我把撤销操作做成异步调度不就行了嘛——在一段时间内(比如五分钟)如果因未找到记录而撤销失败,就稍后重试。
小林的撤销逻辑是这样的:
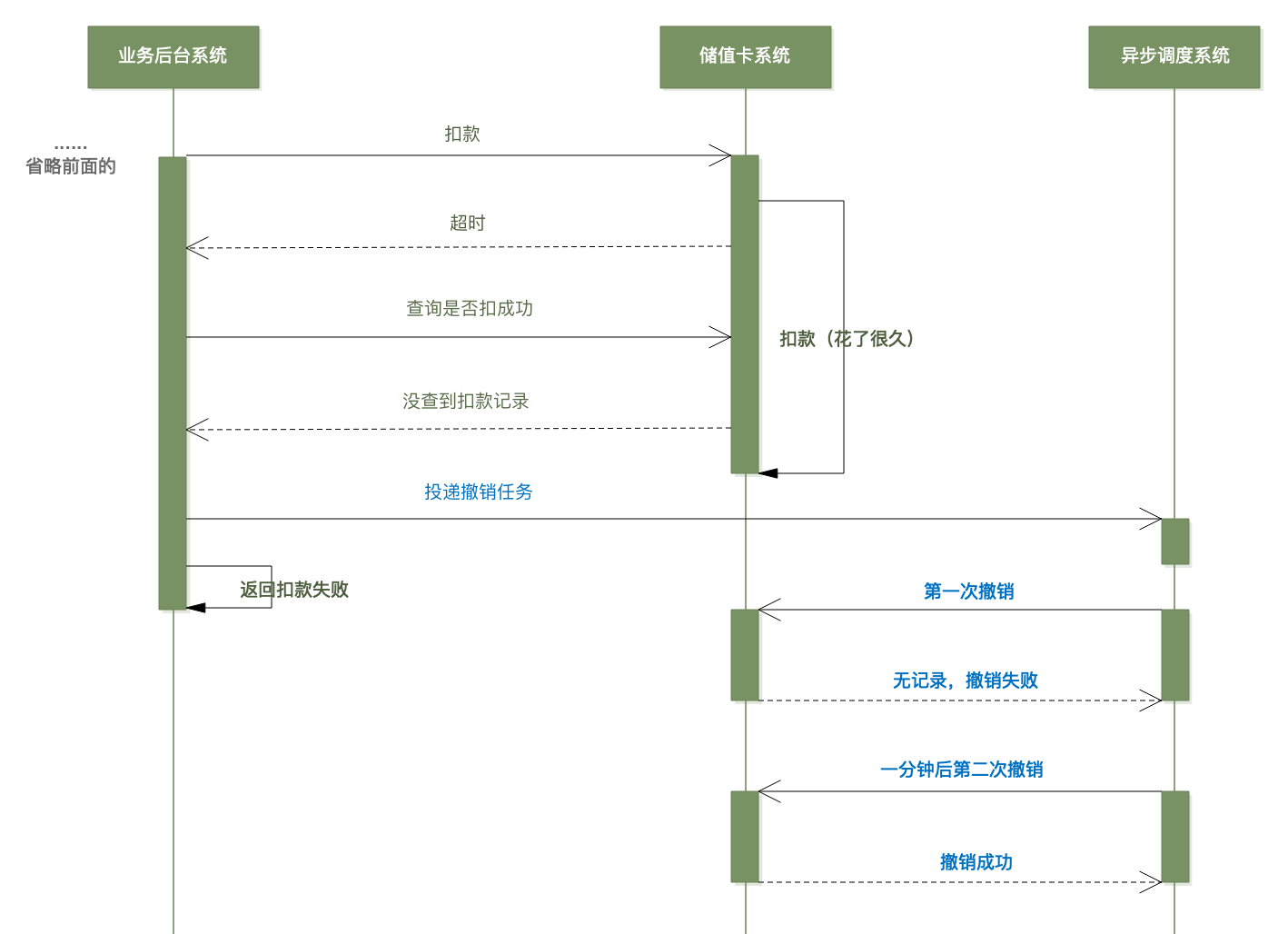
原本由业务系统同步调撤销接口,现在改成走调度系统异步撤销,业务系统投递撤销任务完成后立马返回结果给客户端。
因为有异步重试机制,撤销总是能成功(除了实际中几乎不会发生的极端情况),因而这次一定能保证不会意外扣钱!
小林同学抱着如释重负的心态继续撸猫。
然而,安稳日子没过几天,一个雷电交加的夜晚,手机再次响起:车主储值卡消费的钱莫名其妙给人家退回去了!油站打电话要我们赔偿!
小林赶紧查日志,发现场景是这样的:车主王某用储值卡支付 1000 元油款,失败了;十几秒后车主再次用储值卡发起支付,成功了。
支付最终成功了,莫非人工退钱了?没看到任何退款记录啊?
抓耳挠腮,百思不得其解。小林只能打电话给储值卡系统负责人小李。
小李一顿查日志,最终发现这笔钱是被调度系统调撤销接口给撤销了!
小林如梦方醒,才知道之前自己自鸣得意地犯了个天大的错误。
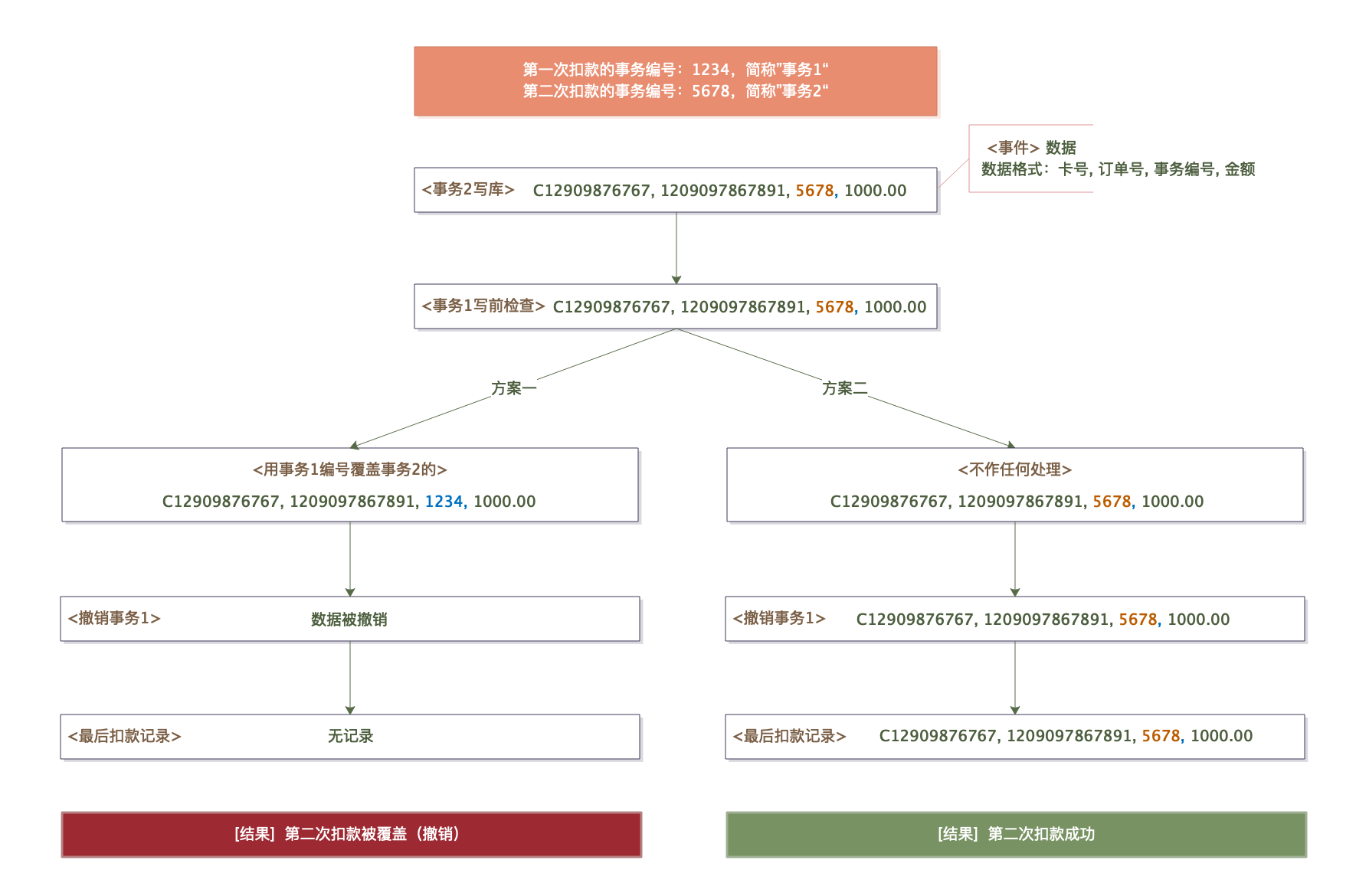
本次消费,业务系统共向储值卡系统发起了两次扣款申请——虽然都是同一笔订单的扣款,却是两个独立的事务。
小林(以及储值卡系统)的错误在于,撤销操作是作用在订单上,而不是事务上。
在本次事故中,第一次扣款超时后,业务系统投递了撤销任务;而后车主又对该笔订单(订单号相同)发起了第二次扣款,成功了;与此同时,调度系统第一次撤销失败(卡系统未找到消费记录,或者接口超时),一段时间后又发起第二次撤销——而这个时候,车主已经完成了第二次扣款且成功了,于是这次的撤销便作用在这个成功的扣款上(储值卡系统的扣款和撤销接口都是根据订单号来的,它能保证同一笔订单不会重复扣款,但撤销的时候无法区分扣款是哪次发起的)。
我们画下流程:
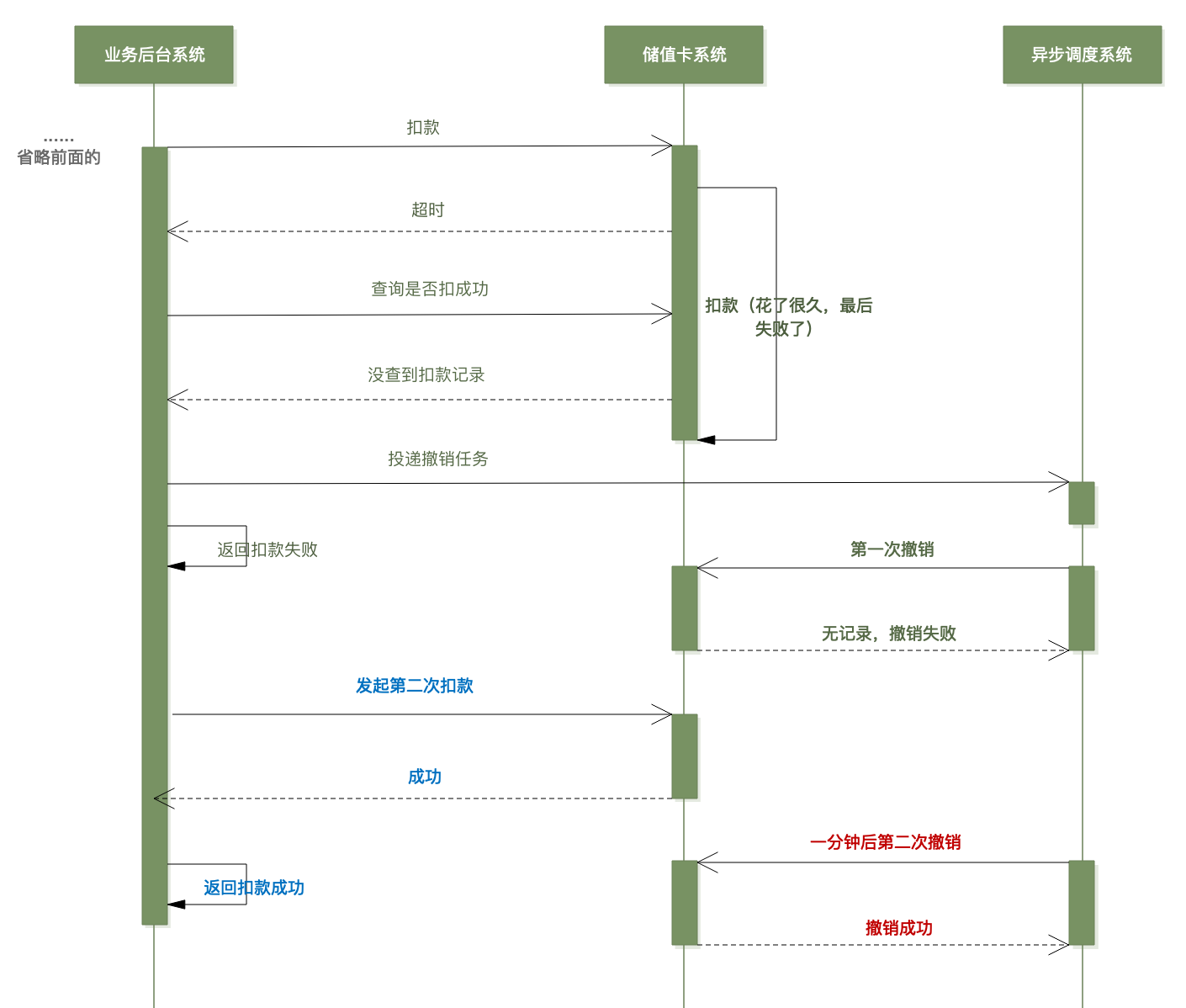
如图,第二次的扣款被调度系统撤销了。
小林和小李这才发现需要给扣款和撤销接口增加事务编号。
之前扣款接口主要参数是 card_no、order_code、amount,现在变成 card_no、order_code、trans_id、amount。
之前撤销接口参数是 order_code,现在变成 order_code、trans_id。
通过 trans_id 将扣款和撤销绑定到同一个操作事务上,只会撤销相应 trans_id 的扣款操作。
trans_id 由客户端根据当前时间毫秒数生成(后面会说为啥取毫秒时间戳),它不一定需要全局唯一,只需要针对同一个订单是唯一的即可。
加了事务的概念后,小林和小李发现压根不需要通过调度系统不断尝试,只要保证撤销接口调成功就能保证对应的扣款事务一定能够被撤销(或者阻止执行)。
现在撤销接口做两件事:
撤销逻辑如下:
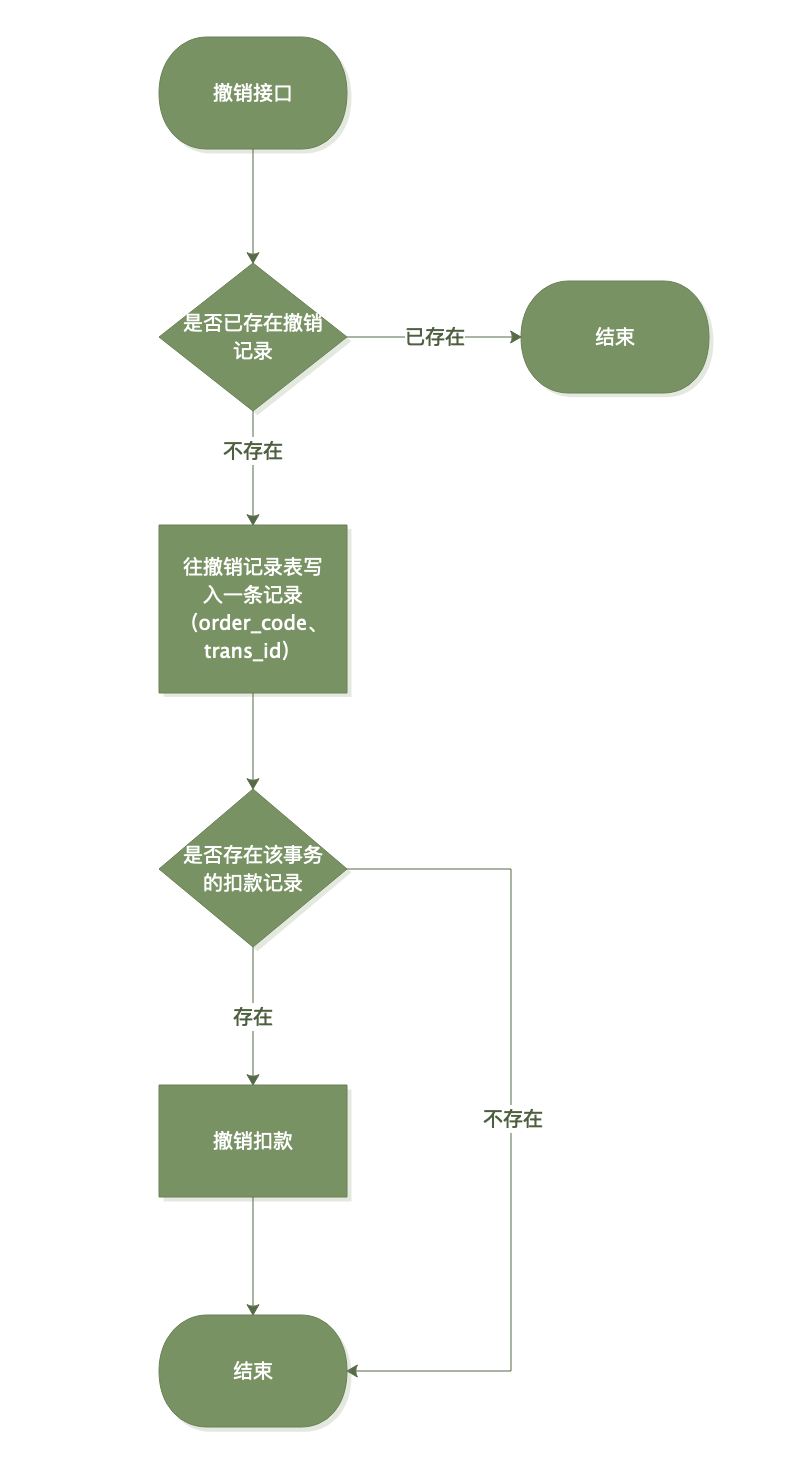
再看看扣款的逻辑。
扣款记录表大致长这样子:

扣款逻辑如下:
流程图如下:
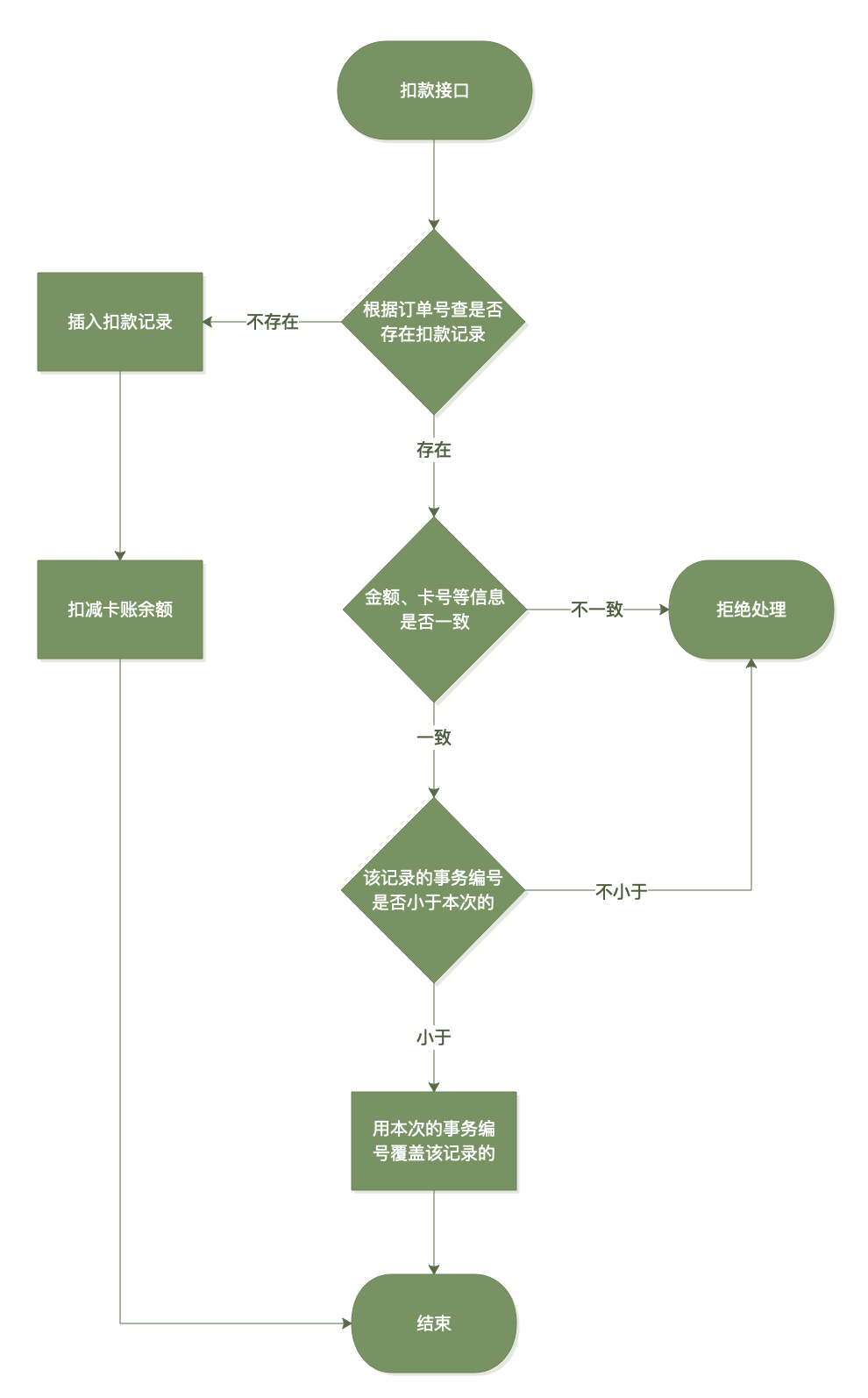
现在我们看看当撤销流程执行时,被撤销的扣款事务处于不同状态下的情况:
由于撤销的时候是按事务编号来的,所以不会撤销别的事务的扣款。
现在我们解释下为何要用当前时间的毫秒时间戳作为事务编号。
回到上面车主王某的场景。王某第一次用卡支付超时,于是他决定重试。该场景中,卡系统接收到同一笔订单的两次扣款事务以及一次撤销事务。假如两次事务都尝试写库,那么当后面的事务(不一定是第二次扣款的那个)尝试写库时,肯定已经存在一条扣款记录,此时后面这个事务要如何做?
两次事务的执行逻辑完全相同,产生的扣款记录数据也是完全相同的——除了事务编号和扣款时间。
这里的关键是,我们无法确定第一次扣款、第二次扣款、对第一次扣款的撤销这三个请求写库的先后顺序。
所以,如果采用方案 1,替换事务编号,那么当第二次的提交先写库时,后面事务(第一次提交的扣款请求)的替换会导致事务编号变成了待撤销的那个,因而很可能会被撤销掉,这就会导致用户付的钱莫名其妙被退回了。
如果采用方案 2,不做任何处理,那么当第一次的提交先写库时,事务编号就一直是待撤销的那个,也会被撤销掉,导致用户付的钱莫名其妙被退回。
也就是说,无脑替换或不替换都是有问题的。
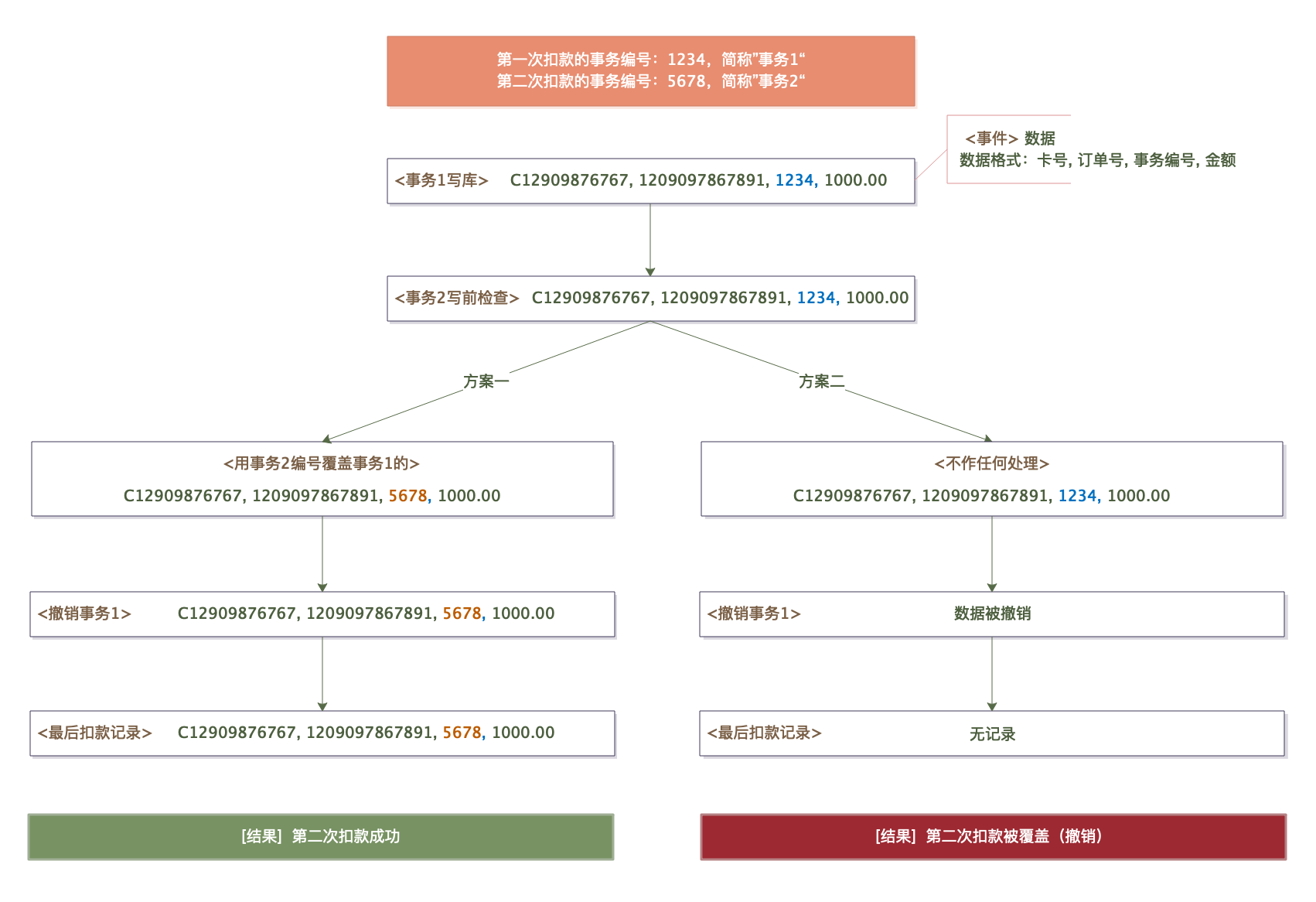
第一次扣款事务先写库的情况
第二次扣款事务先写库的情况
实际的业务场景是,对于同一笔订单,无论发出多少次扣款请求,只允许一次成功,而且这次成功的扣款不能被误撤销。有很多方案可以实现这一点,不过有些方案需要增加额外表,有些则需要为同一笔订单维护多条扣款记录,这些都会带来额外的复杂性。
我们采取事务序列号(毫秒时间戳)的方式来保证扣款事务的时序性,只允许后面覆盖前面的,不允许反过来覆盖。其基于这样的事实:用户如果对同一笔订单发出多次扣款请求,那一定是前面扣款失败了,因而业务系统会为前面那些失败的扣款发出撤销请求,所以只要保证仅允许后面覆盖前面的事务,就不会造成误撤销(因为唯有最后那个扣款事务不会存在撤销请求。感兴趣的可参照上面的图示推演一下)。
这里说的事务是指一次扣款处理流,不是指数据库事务。
我不想编程了,说真的,这么个简单的扣款场景就扯出这么多幺蛾子,太难了!
现实中比这复杂的场景多得是。
程序员到底是怎么活下来的?
答案是,他们的一生是在没完没了的 bug 中度过的。
90% 以上的 bug 都是因为对失败场景考虑不周导致。
如果把现实看成事件流,那么事件流中的绝大多数节点都有不止一个出口分支(典型的是”正常“和”异常“)。2022 年 4 月 30 日晚,小林同学可能躺在床上玩游戏,也可能躺在 ICU。
系统(特别是业务系统)是对现实世界业务的反映,每个节点同样存在多种可能。
典型的业务流分析步骤是这样的:
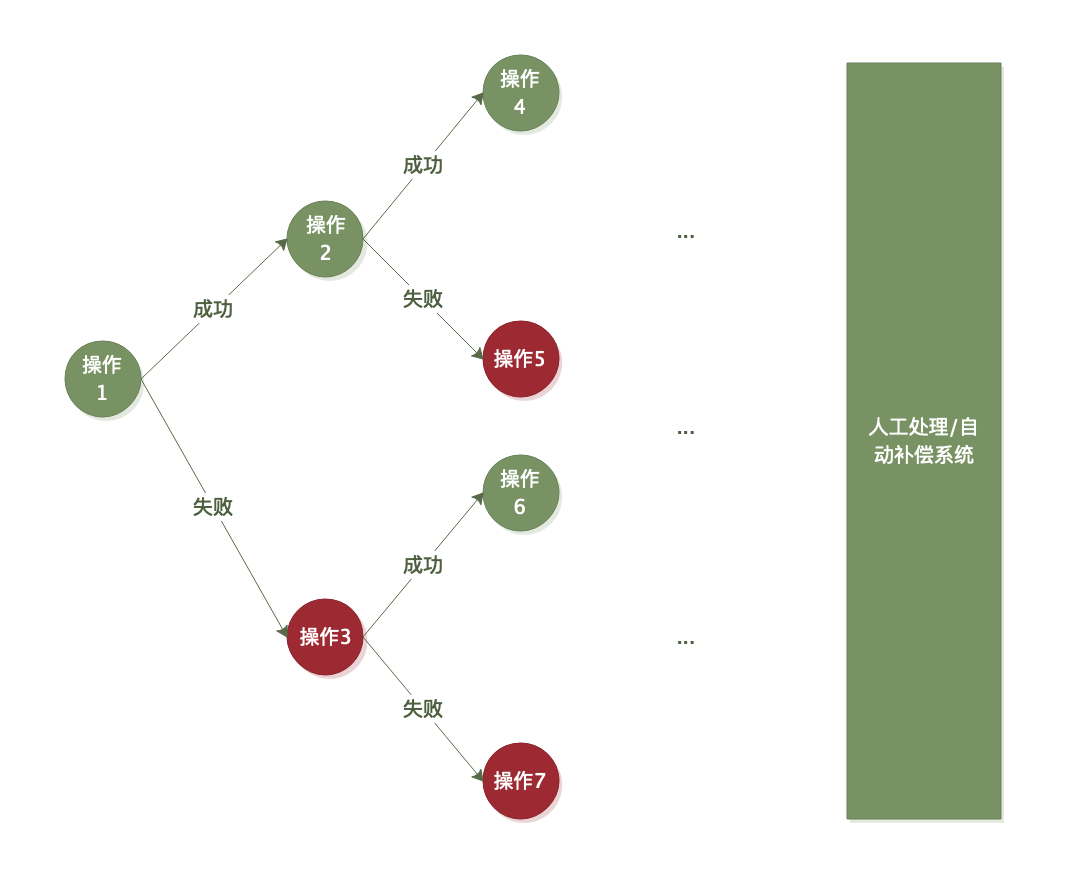
几乎所有的结点都要考虑失败场景,而对于一些失败场景的补偿措施仍然可能失败,如此递归,最终由自动补偿系统(如漏单检测/补偿系统)或人工处理来兜底。
失败的一大重要根源是分布式。
不要提什么单体架构,做 web 开发的,自入行第一天起就面对分布式系统。
典型的分布式是前后端交互。自 ajax 出世以来,前后端接口交互成为常态,接口失败也是每个程序员都会遇到的问题。很大部分的前后端交互失败的场景没有得到很好地处理(特别是超时),比如没有去重,导致重复写入数据。
自从微服务横行以来,后端开发人员无不被分布式事务搞得焦头烂额。业界也总结了些解决方案,比如两阶段提交、SAGA、TCC 等,但真正实现起来都不简单,一个看似简单的业务都会搞得很复杂。所以业界又搞了些现成的开源方案如 seata、DTM。
好消息是,不是所有的系统都需要那么高的可靠性保证,也不是所有的失败场景都要做补偿处理。
你可能是在一家初创公司,别说系统一分钟不可用了,就是库被删了估计也没事。
你做的系统可能只是给内部人员用用,凡是遇到失败就抛异常,大不了人工去修复数据也是可以的。
这些情况下,很可能你并不需要去开发高可用系统,他们更讲究效率,把正常流程码出来基本就完事了。
讲究点可用性的,稍微把代码写好点,服务器配置堆高点,业务流程设计上注意点,基本也能规避大部分祭天性的问题。
等你公司真的发展成 BAT 那种了,是真正拼刀工的时候,万分之一概率的异常场景可能就会让系统天天宕机,账户天天少钱。那时候各种方案、架构、分析都要拿到桌面上来了。
所以,面向失败编程诚然很难,但不代表你必须得天天面对着失败抓耳挠腮,你需要评估你所负责的系统在成本、效率、健壮性上应做怎样的取舍。






