
前置说明
- 遍历文件夹下的文件,读取所有的sheet页(指定的sheet)落库
- 读取execl文件和csv文件,获得文件中sheet/csv数据,进行落库,并增加字段实现更新;
- 如果execl中存在两个标题,将标题一进行
行转列并进行字段的添加(任务图如下)

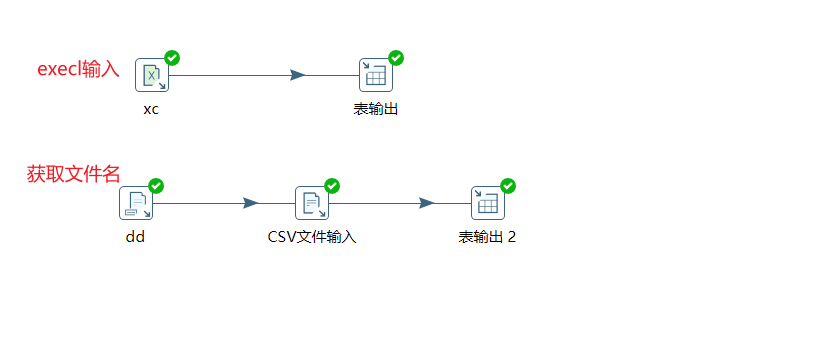
最终实现效果图:

组件的使用:

- execl输入
- csv输入
- 获取文件名
- 表输出
- 列拆分为多行
- 记录合并(笛卡尔积)
- 转换
- 执行SQL语句
说明:
任务1:使用滴滴.csv和携程(xc.xlsx)做演示
任务2:使用京东(jd1.xlsx)做演示
场景复现:

搭建任务1:使用滴滴.csv和携程(xc.xlsx)做演示
流程:
携程:
Execl文件输入:

文件输出,需要执行对应的路径,通过通配符进行匹配文件夹下的所有文件;.*.xlsx
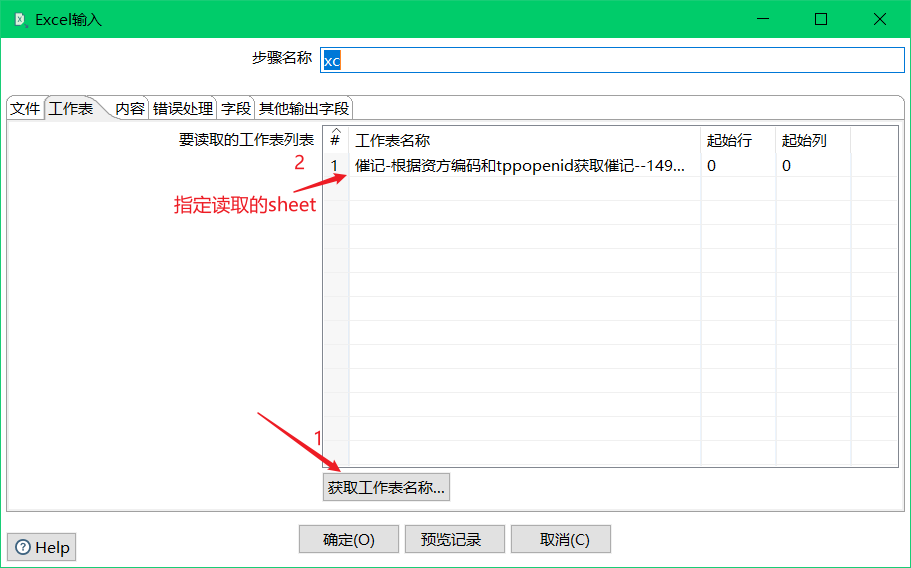
这里需要注意,对于工作表来说,可用于两个场景:

- 读取指定的sheet数据
- 不指定sheet名字则读取该execl文件中所有的sheet数据,字段需要一致(适用于文件下的sheet页名字不同字段相同的表数据)
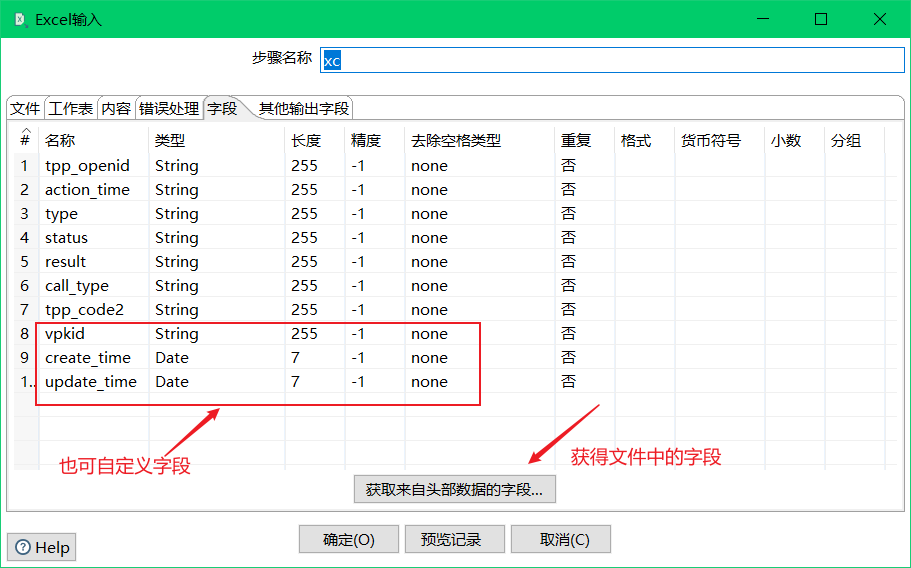
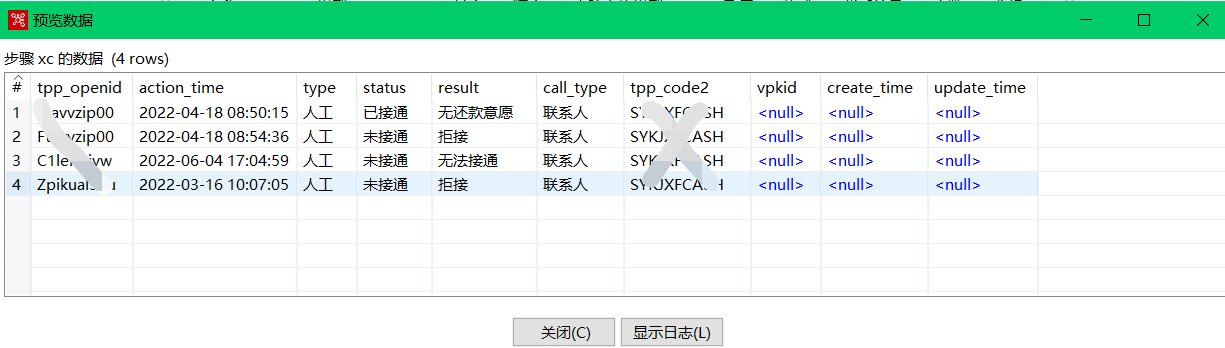
表输出:
直接以该组件图展示来说;
首先需要连接数据库(可参考网上文章),选择目标表,这里有两种方式:
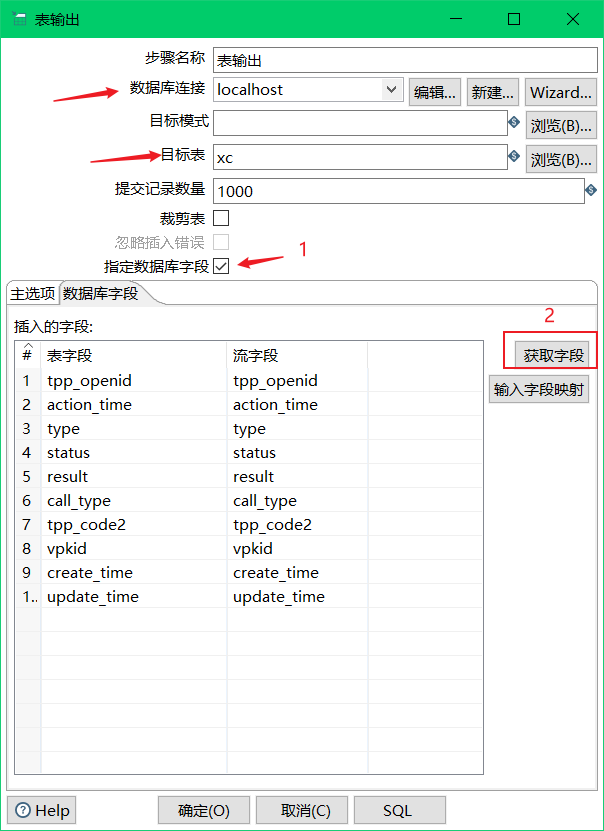
- 如果数据库中存在表,则直接选择或填写名字
- 如果数据库没有,则开启指定数据库字段,并获取字段,执行下面的SQL,需要注意的是自动生成的语句是否正确。
最后执行可看到效果;
滴滴
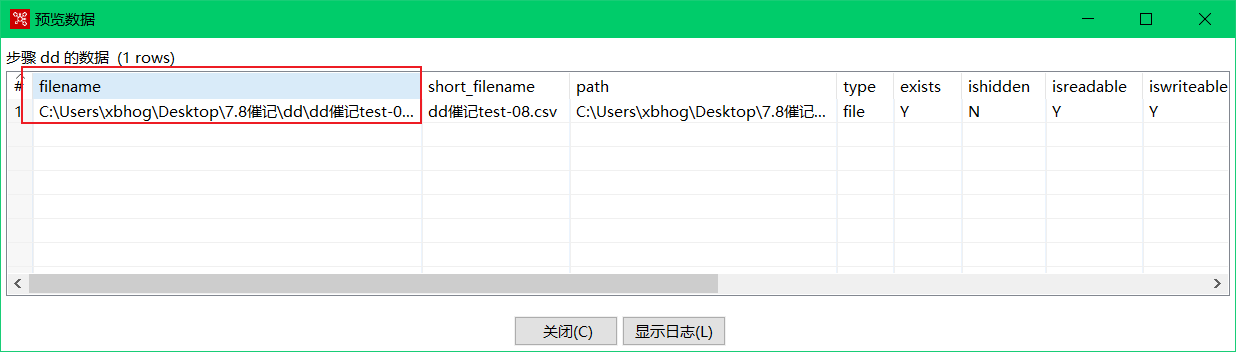
获取文件名:

获取文件名匹配类似与execl输入组件,在预览数据的时候需要注意的filename参数,后续用到。
CSV文件输入:
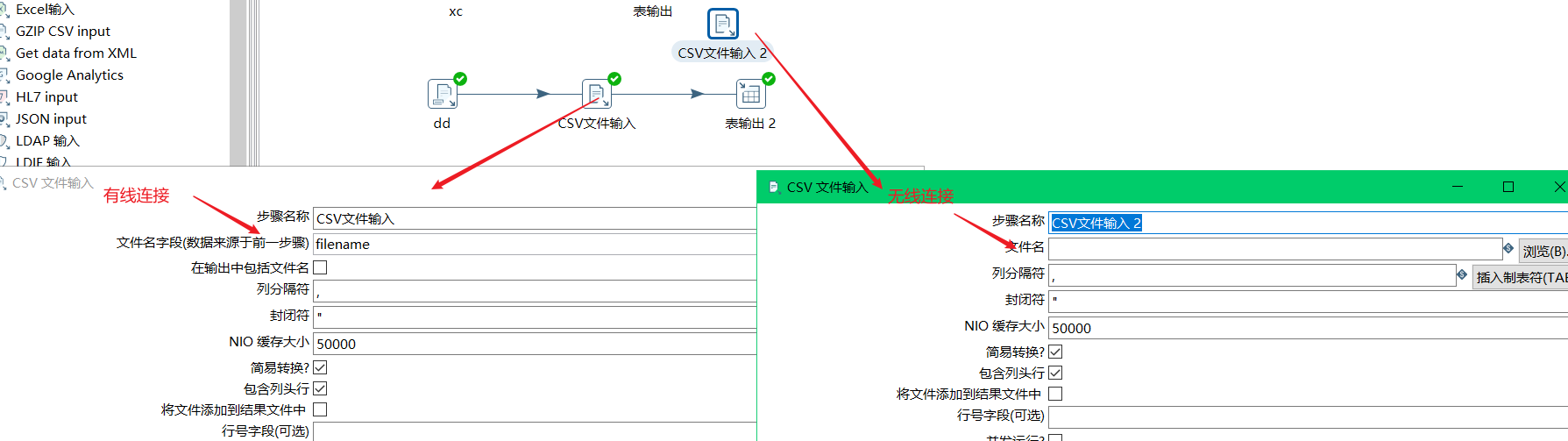
首先通过单一的CSV文件输入,获得对应文件中的字段:

然后连接到获取文件名,通过filename参数,来接收前面的文件名;
最后表输出与携程例子中的操作相同,不表。

搭建任务2:使用京东(jd1.xlsx)做演示
流程图:
如果execl中存在两个标题,将标题一进行行转列并进行字段的添加。
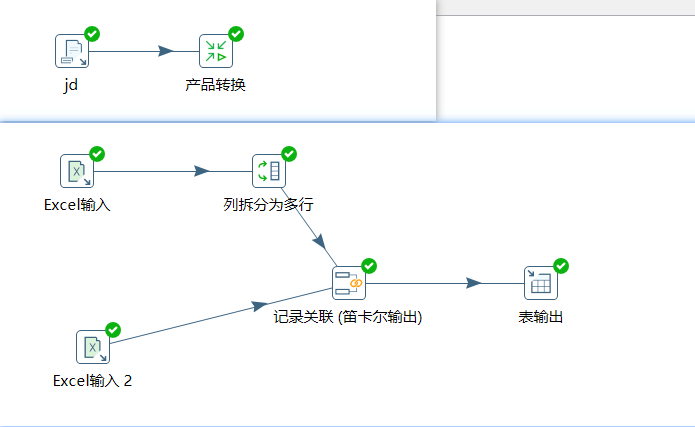
在获取文件名中得到文件名参数(filename),需要传递到转换中:

Execl输入组件中的配置参数;
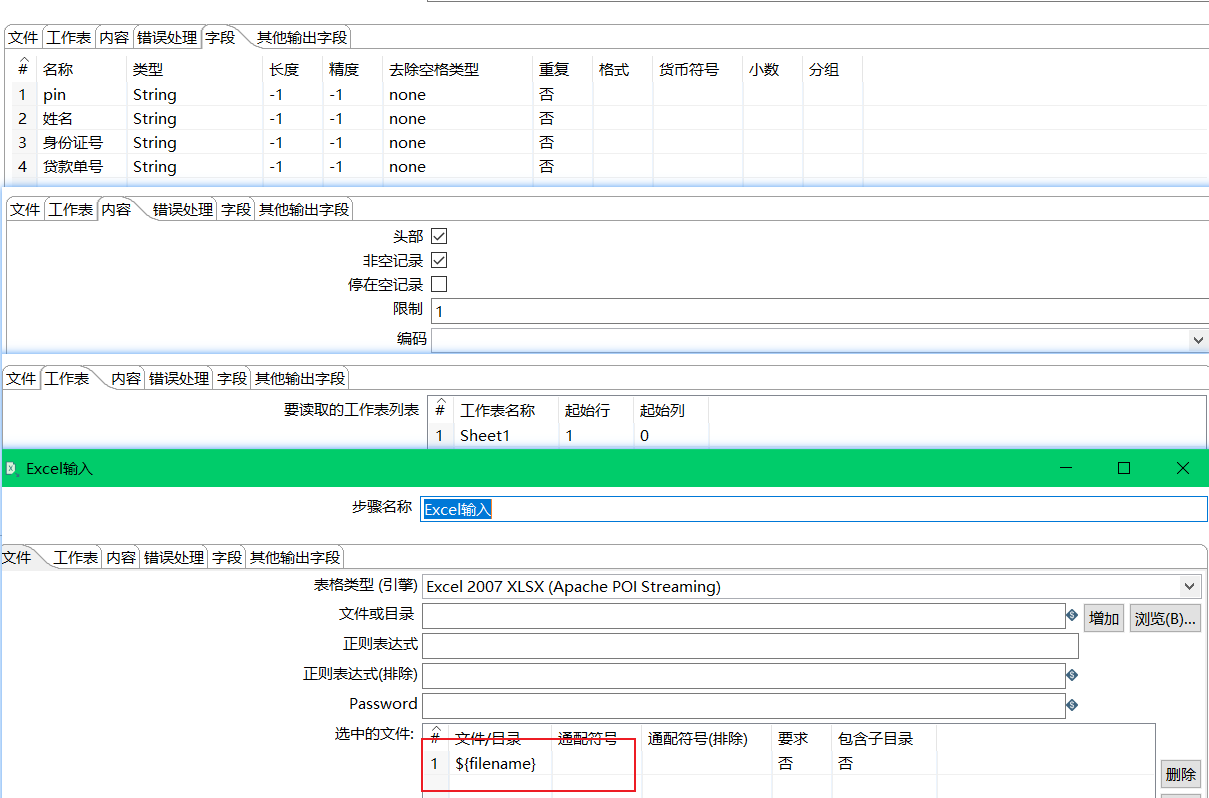
为了实现将第一个标题下的数据读取出来并进行行转列。我们在输入组件中的内容部分,设置为限制1:表示只读取标题字段下的第一行。(如下图)

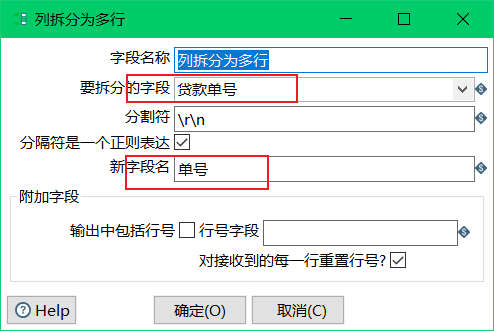
根据列拆分多行进行转换:选择前面的字段,并设置向后传递的字段名字。
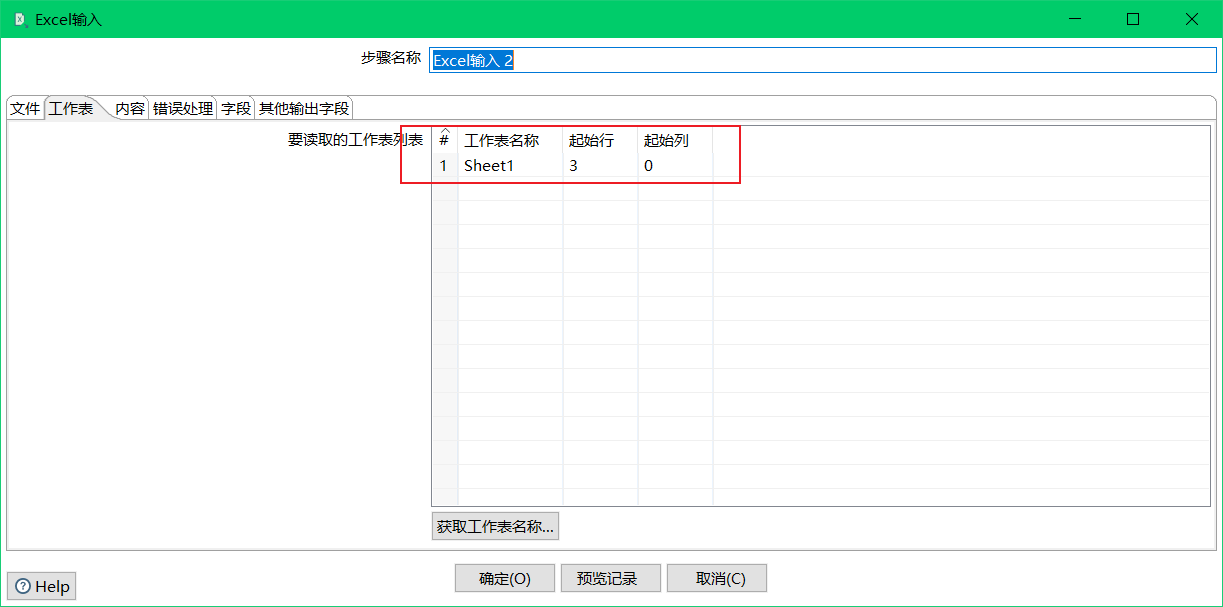
Execl2输入组件需要注意的点是sheet数据读取的起始位置:
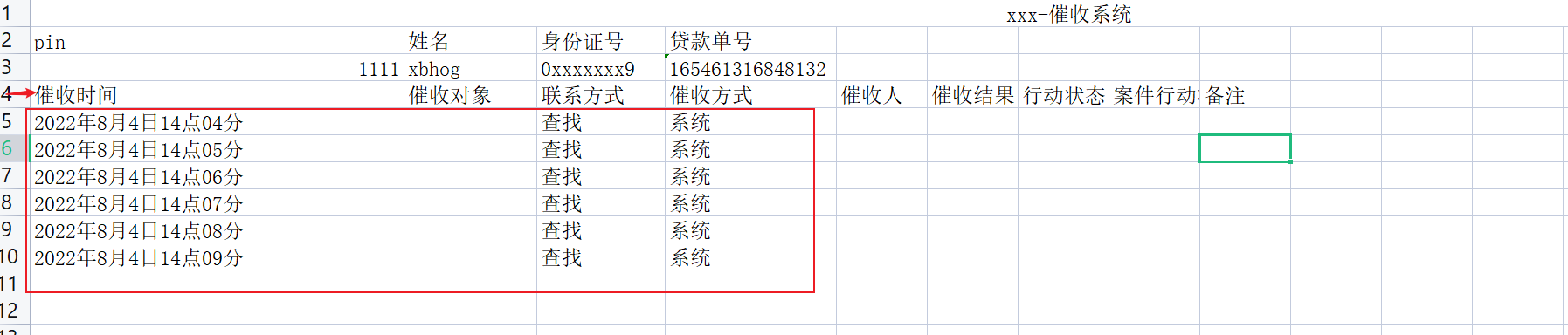
最后对数据进行组合和落库:记录关联直接拖出来用就可。
字段更新
update xc set vpkid=CONCAT(DATE_FORMAT(SYSDATE(),'%Y%m%d'), 'xc'),update_time=SYSDATE(),create_time=SYSDATE(); 最后对入库数据的各表字段进行更新:


Linux下运行
./pan.sh -file=xxx.ktr ./kitchen.sh -file=xxxx.kjb kettle基于Java开发,可设置JVM内存大小:
起始内存大小:Xms
最大内存大小:Xmx
永久代大小:MaxpermSize
if "%PENTAHO_DI_JAVA_OPTIONS%"=="" set PENTAHO_DI_JAVA_OPTIONS="-Xms7680m" "-Xmx7680m" "-XX:MaxPermSize=3840m" 




