
执行模型
执行模型(Processing Model)定义了数据库系统如何执行一个查询计划。
Iterator Model
基本思想:采用树形结构组织操作符,然后中序遍历执行整棵树,最终根结点的输出就是整个查询计划的结果。
每个操作符(Operator)实现如下函数:
Next()- 返回值:一个tuple或者EOF。
- 执行流程:循环调用孩子结点的
Next()函数。
Open()和Close():类似于构造和析构函数。


输出从底部向顶部(Bottom-To-Top)汇聚,且支持流式操作,所以又称为Valcano Model,Pipeline Model。
Materialization Model
基本思想:操作符不是一次返回一个数据,暂存下所有数据,一次返回给父结点。
相比于Iterator Model,减少了函数调用开销,但是中间结果可能要暂存磁盘,IO开销大。
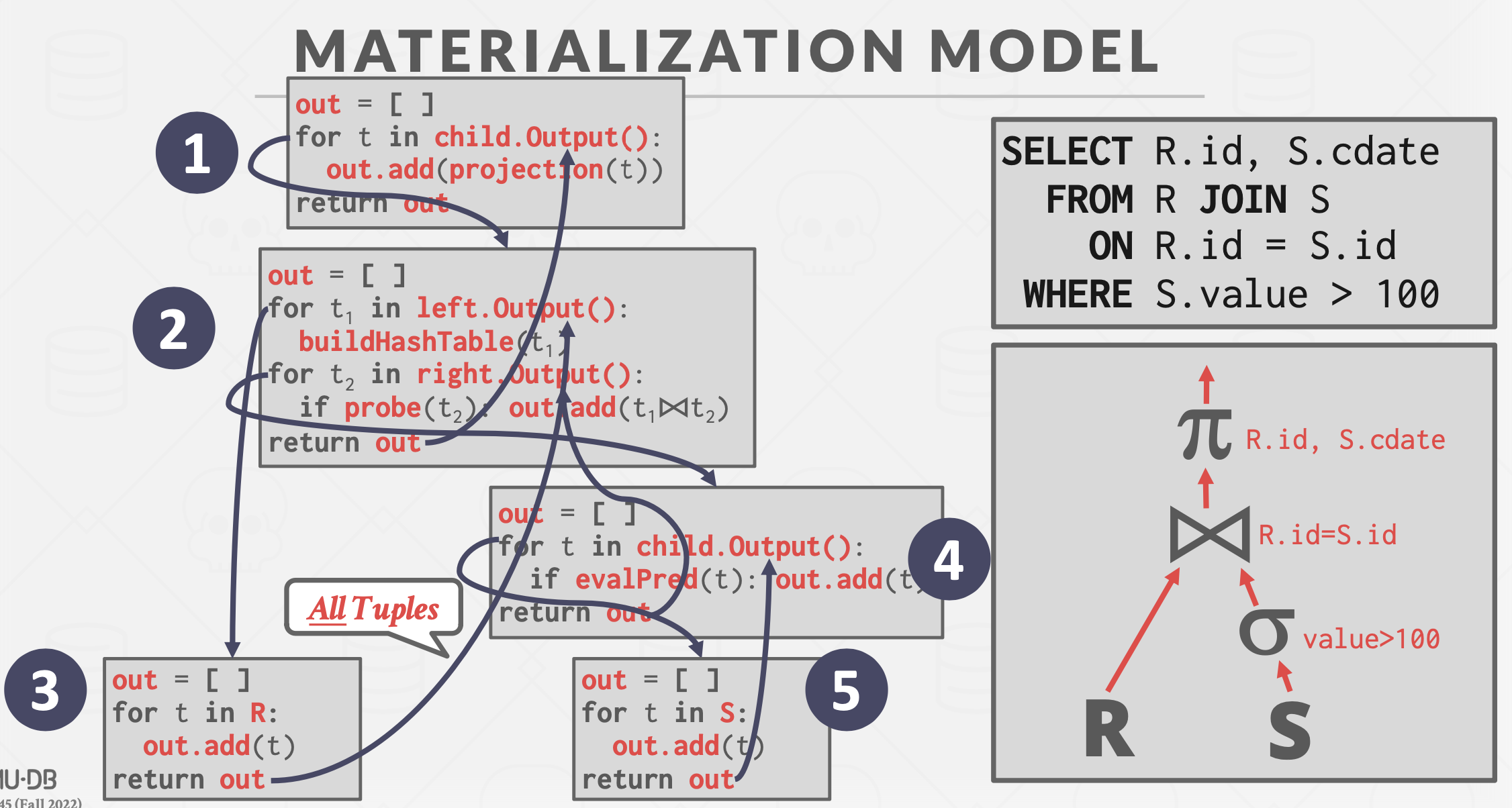
可以向下传递一些暗示(hint),如Limit,避免扫描过多的数据。
更适用于OLTP而不是OLAP。
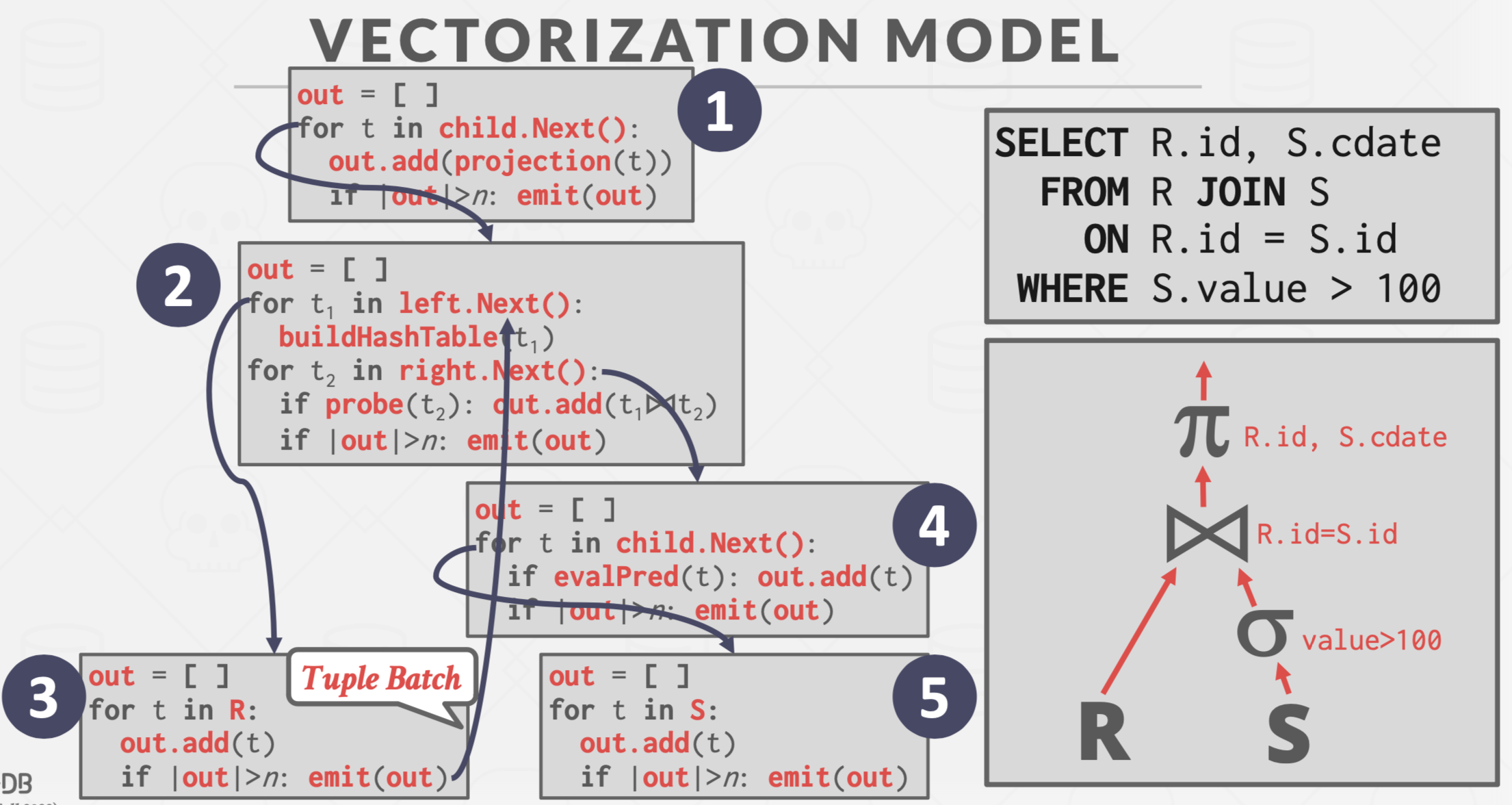
Vectoriazation Model
基本思想:操作符返回一批数据。
结合了Iterator Model和Materialization Model的优势,既减少了函数调用,中间结果又不至于过大。
可以采用SIMD指令加速批数据的处理。
对比
| 特性 | Iterator Model | Materialization Model | Vectorization Model |
|---|---|---|---|
| 数据处理单位 | 单条记录(tuple-at-a-time) | 整个中间结果(table-at-a-time) | 批量记录(vector/batch-at-a-time) |
| 性能 | 函数调用开销高,效率低 | 延迟高,内存/I/O 开销大 | 函数调用开销低,SIMD 加速性能优异 |
| 内存使用 | 内存需求低 | 内存需求高 | 中等 |
| I/O 开销 | 低 | 高 | 中等 |
| 缓存利用率 | 差 | 差 | 高 |
| 复杂性 | 实现简单 | 中等 | 实现复杂 |
| 适用场景 | 小型数据集,流式处理 | 中间结果复用的复杂查询 | 大型数据集,需高性能计算的场景 |
数据访问方式
主要有三种数据访问方式:
- 全表扫描(Sequential Scan)
- 索引扫描(Index Scan)
- 多索引扫描(Multi-Index Scan)
Sequential Scan
全表扫描的优化手段:

Data Skipping方法:
- 只需要大致结果:采样估计。
- 精确结果:Zone Map

Zone Map基本思想:化整为零,提前对数据页进行聚合。
执行 Select * From table Where val > 600时,下面的页可以直接跳过。

Index Scan
如何确定使用哪个索引:数据分布。

Multi-Index Scan
基本思想:根据每个索引上的谓词,独立找到满足条件的数据记录(Record),然后根据连接谓词进行操作(并集,交集,差集等)。

Halloween Problem
对于UPDATE语句,需要追踪更新过的语句,否则会出现级联更新的问题。

<999, Andy>执行更新,走索引扫描:
- 移除索引
- 更新Tuple,<1099, Andy>
- 插入索引
- (约束检查)
此时,如果不对<1099, Andy>进行标记,他满足Where子句,会被重新更新一次。
表达式求值
基本思想:采用树形结构,构建表达式树,用中序遍历方式执行所有求值动作,根结点的求值结果就是最终值。

数据库中哪些地方采用了树结构:
- B+树:存储。
- 树形结构+中序遍历求值:查询计划,表达式求值。
优化手段:JIT Compilatoin。将热点表达式计算结点视为函数,编译为内联机器码,而不是每次都遍历结点。

并行执行
处理模型
-
基于进程(早期)

-
基于线程(主流)
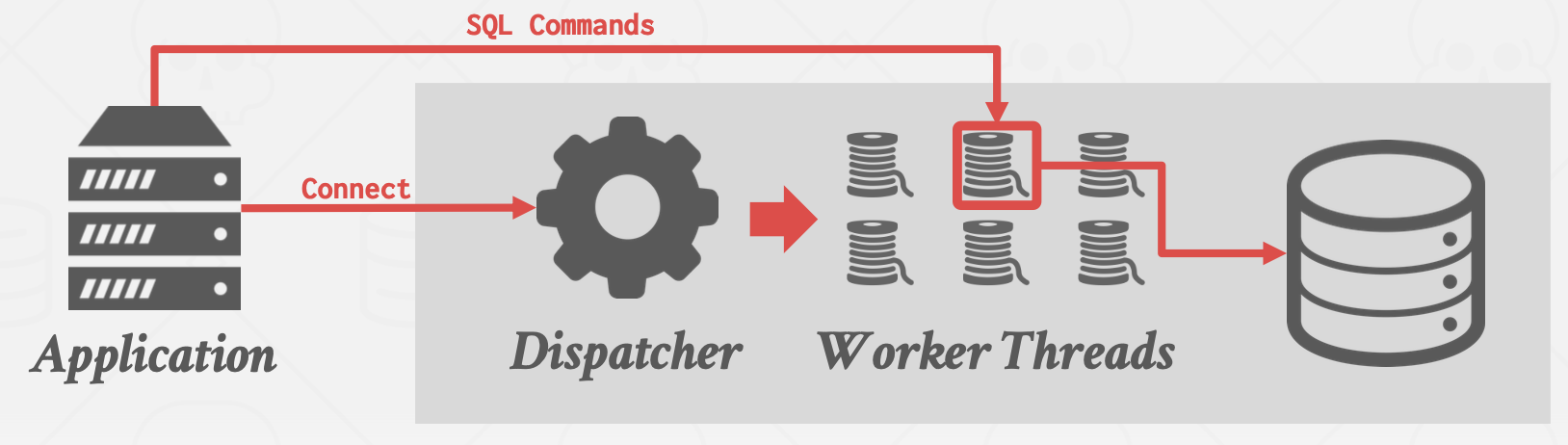
-
嵌入式场景:应用直接管理需要的worker(进程/线程)

并行处理
主要分Inter-Query Parallelism(查询间并行)和Intra-query Paralleliszm(查询内并行),属于两种不同的并行方式,可以相互结合。
| Inter-query Parallelism | Intra-query Parallelism | |
|---|---|---|
| 并行粒度 | 查询级别 | 查询内的操作或数据级别 |
| 目标 | 提高系统吞吐量 | 减少单个查询的执行时间 |
| 实现难度 | 简单,查询独立运行 | 复杂,需要任务分解、调度和同步 |
| 资源竞争 | 查询间可能有资源竞争 | 查询内任务间可能有资源竞争 |
| 适用场景 | 多用户、事务处理(如 OLTP)场景 | 大规模查询、复杂分析(如 OLAP)场景 |
Intra-query Parallelism内部实现操作并行的时候,又可以划分为以下两种方式,以及两种方式的结合Bushy Parallelism
| Inter-operator Parallelism | Intra-operator Parallelism | |
|---|---|---|
| 并行粒度 | 操作之间的并行:不同的查询操作(例如选择、连接、聚合等)同时执行。 | 单个操作内部的并行:将一个操作(例如连接或聚合)分解为多个并行任务执行。 |
| 实现方式 | 操作按 流水线 顺序执行,不同操作由不同线程或节点处理。 | 单个操作分解成多个子任务,子任务在多个线程或节点上并行执行。 |
| 资源利用 | 各个操作之间分开利用资源,任务分配相对简单。 | 单个操作内部高效利用所有可用资源,任务分配更加复杂。 |
| 适用场景 | 适用于查询中包含多个操作的情况。 | 适用于单个操作(尤其是代价较高的操作,如大规模连接)。 |
| 复杂度 | 相对较低,只需要协调操作的执行顺序和调度。 | 更复杂,需要对操作内部任务分解、分布和结果合并。 |










