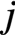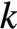CPU AMX 详解
概述
2016 年开始,随着 NV GPU AI 能力的不断加强,隐隐感觉到威胁的 Intel 也不断在面向数据中心的至强系列 CPU 上堆砌计算能力,增加 core count 、提高 frequency 、增强向量协处理器计算能力三管其下。几乎每一代 CPU 都在 AI 计算能力上有所增强或拓展,从这个方面来讲,如果我们说它没认识到势,没有采取行动,也是不公平的。

从上图不难看到,2015年的 Sky Lake 首次引入了 AVX-512 (Advanced Vector eXtensions)向量协处理器,与上一代 Broadwell 的 AVX2 相比, 每个向量处理器单元的单精度浮点乘加吞吐翻倍。接着的Cascade Lake 和 Cooper Lake又拓展了 AVX-512 ,增加了对 INT8 和 BF16 精度的支持,奋力想守住 inference 的基本盘。一直到 Sapphire Rapids,被市场和客户用脚投票,前有狼(NVIDIA)后有虎(AMD),都把自己的食盆都快拱翻了,终于意识到在AI的计算能力上不能在按摩尔定律线性发育了,最终也步Google和NVIDIA的后尘,把AVX升一维成了AMX(Advanced Matrix eXtension),即矩阵协处理器了。充分说明一句老话,你永远叫不醒一个装睡的人,要用火烧他。不管怎么样,这下总算是赛道对齐了,终于不是拿长茅对火枪了。


算力如何
AI 工作负载 Top-2 的算子:
-
Convolution
-
MatMul/Fully Connected
这俩本质上都是矩阵乘。怎么计算矩阵乘,有两种化归方法:
-
化归成向量点积的组合,这在CPU中就对应AVX
-
化过程分块矩阵乘的组合,这在CPU就对应AMX
我们展开讲讲。
问题定义
假设有如下矩阵乘问题:


AVX如何解决矩阵乘问题

AVX把向量作为一等公民,每次计算一个输出元素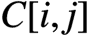 ,而该元素等于
,而该元素等于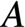 的第
的第行与
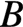 的第列的点积,即有:
的第列的点积,即有: