
在上一篇文章中我们介绍了使用 Tesseract 如何识别格式规范的文字,在这篇文章中我们将详细介绍使用 Tesseract 如何识别图像验证码。
虽然大多数人对单词“CAPTCHA”都很熟悉,但是很少人知道它的具体含义:全自动区分计算机和人类的图灵测试(Completely Automated Public Turing test to tell Computers and Humans Apart)。它的奇怪缩写似乎表示,它一直在扮演着十分奇怪的角色。其目的是为了阻止网站访问,而不是让访问更通畅,它经常让人类和非人类的网络机器人深陷验证码识别的泥潭不能自拔。
图灵测试首次出现在阿兰·图灵(Alan Turing)1950 年发表的论文“计算装置与智能”(Computing Machinery and Intelligence)中。他在论文中描述了这样一种场景:一个人可以和其他人交流,也可以通过计算机终端和人工智能程序交流。如果一番对话之后这个人不能区分人和人工智能程序,那么就认为这个人工智能程序通过了图灵测试,图灵认为这个人工智能程序就可以真正地“思考”所有的事情。
令人啼笑皆非的是,60多年以后,我们开始用这些原本测试程序的题目来测试我们自己。Google 的 reCAPTCHA 难得令人发指,作为目前最具有安全意识的流行网站,Google 拦截了多达 25% 的准备访问网站的正常人类用户。
大多数其他的验证码都是比较简单的。例如,流行的 PHP 内容管理系统 Drupal 有一个名的验证码模块,可以生成不同难度的验证码。默认图片如图下图所示:
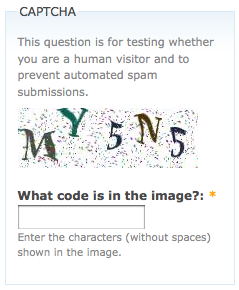
那么与其他验证码相比,究竟是什么让这个验证码更容易被人类和机器(爬虫)读懂呢?
母外面画一个方框,而不会重叠在一起。
图片没有背景色、线条或其他对 OCR 程序产生干扰的噪点。
虽然不能因一个图片下定论,但是这个验证码用的字体种类很少,而且用的是 sans-serif(无衬线字体) 字体(像“4”和“M”)和一种手写形式的字体(像“m”“C”和“3”)。
白色背景色与深色字母之间的对比度很高。
上面验证码只做了一点点改变,就让 OCR 程序很难识别。
字母和数据都使用了,这会增加待搜索字符的数量。
字母随机的倾斜程度会迷惑 OCR 软件,但是人类还是很容易识别的。
那个比较陌生的手写字体很有挑战性,背景加了一些噪点,同时“M”和”Y“都进行了变换,计算机需要进行额外的训练才能识别。
用下面的代码运行 Tesseract 识别图片:
E:Tesseract-OCR>tesseract.exe "E:我的文档My PicturesSaved Picturesimage_captcha_example.max_239x290.png" "E:我的文档My PicturesSaved Pictures1.txt" 我们得到的结果是一个空文本文件,有换行符。
要训练 Tesseract 识别一种文字,无论是晦涩难懂的字体还是验证码,你都需要向 Tesseract 提供每个字符不同形式的样本。
做这个枯燥的工作可能要花好几个小时的时间,你可能更想用这点儿时间找个好看的视频或电影看看。首先要把大量的验证码样本下载到一个文件夹里。下载的样本数量由验证码的复杂程度决定,我在训练集里一共放了100个样本(一共 500 个字符,平均每个字符 8 个样本;a~z 大小写字母加 0~9 数字,一共 62 个字符),应该足够训练的了。
提示:建议使用验证码的真实结果给每个样本文件命名(即 4MmC3.jpg)。这样可以帮你一次性对大量的文件进行快速检查——你可以先把图片调成缩略图模式,然后通过文件名对比不同的图片。这样在后面的步骤中进行训练效果的检查也会很方便。
第二步是准确地告诉 Tesseract 一张图片中的每个字符是什么,以及每个字符的具体位置。这里需要创建一些矩形定位文件(box file),个验证码图片生成一个矩形定位文件。一个验证码图片的矩形定位文件如下所示:
A 11 5 46 36 0 c 47 9 69 32 0 r 75 10 94 32 0 E 105 8 131 43 0 第一列符号是图片中的每个字符,后面的4个数字分别是包围这个字符的最小矩形的坐标(图片左下角是原点(0,0),4个数字分别对应每个字符的左下角 x 坐标、左下角 y 坐标、右上角 x 坐标和右上角 y 坐标),最后一个数字“0”表示图片样本的编号。
显然,手工创建这些图片矩形定位文件很无聊,不过有一些工具可以帮你完成。
矩形定位文件必须保存在一个 .box 后缀的文本文件中。和图片文件一样,文本文件也是用验证码的实际结果命名(例如:4MmC3.box)。另外,这样便于检查 .box 文件的内容和文件的名称,而且按文件名对目录中的文件排序之后,就可以让 .box 文件与对应的图片文件的实际结果进行对比。
你还需要创建大约 100 个 .box 文件来保证你有足够的训练数据。因为 Tesseract 会忽略那些不能读取的文件,所以建议你尽量多做一些矩形定位文件,以保证训练足够充分。如果你觉得训练的 OCR 结果没有达到你的目标,或者 Tesseract 识别某些字符时总是出错,多创建一些训练数据然后重新训练将是一个不错的改进方法。
创建完满载 .box 文件和图片文件的数据文件夹之后,在做进一步分析之前最好备份一下这个文件夹。虽然在数据上运行训练程序不太可能删除任何数据,但是创建.box 文件用了你好几个小时的时间,来之不易,稳妥一点儿总没错。此外,能够抓取一个满是编译数据的混乱目录,然后再尝试一次,总是好的。
完成所有的数据分析工作和创建 Tesseract 所需的训练文件,一共有六个步骤。有一些工具可以帮你处理图片和 .box 文件,不过目前 Tesseract 3.02 还不支持。
我再 github 上找到了一个 Python 版的解决方案来处理同时包含图片文件和 .box 文件的数据文件夹,然后自动创建所有必需的训练文件。
这个解决方案的主要配置方式和步骤都在 main 方法(目前,作者已经在 GitHub 中将示例代码修改为 __init__ 方法,符合 Python 的类定义原则)和 runAll 方法里:
from PIL import Image import subprocess import os # Steps to take before running: # Set TESSDATA_PREFIX to correct directory # Put image and box files together in the same directory # Label each corresponding file with the same filenames class TesseractTrainer: def __init__(self): new_path = os.path.join(os.getcwd(), 'a_z\') self.languageName = "eng" self.fontName = "captchaFont" self.directory = new_path self.trainingList = None self.boxList = None def runAll(self): self.createFontFile() # self.cleanImages() self.renameFiles() self.extractUnicode() self.runShapeClustering() self.runMfTraining() self.runCnTraining() self.createTessData() def cleanImages(self): print("CLEANING IMAGES...") files = os.listdir(self.directory) for fileName in files: if fileName.endswith("tif") or fileName.endswith("jpeg") or fileName.endswith("png"): image = Image.open(self.directory + "/" + fileName) # # Set a threshold value for the image, and save # image = image.point(lambda x: 0 if x < 250 else 255) (root, ext) = os.path.splitext(fileName) newFilePath = root + ".tiff" image.save(self.directory + "/" + newFilePath) # Looks for box files, uses the box filename to find the corresponding # .tiff file. Renames all files with the appropriate "<language>.<font>.exp<N>" filename def renameFiles(self): files = os.listdir(self.directory) boxString = "" i = 0 for fileName in files: if fileName.endswith(".box"): (root, ext) = os.path.splitext(fileName) tiffFile = self.languageName + "." + self.fontName + ".exp" + str(i) + ".tiff" boxFile = self.languageName + "." + self.fontName + ".exp" + str(i) + ".box" os.rename(self.directory + "/" + root + ".tiff", self.directory + "/" + tiffFile) os.rename(self.directory + "/" + root + ".box", self.directory + "/" + boxFile) boxString += " " + boxFile self.createTrainingFile(self.languageName + "." + self.fontName + ".exp" + str(i)) i += 1 return boxString # Creates a training file for a single tiff/box pair # Called by renameFiles def createTrainingFile(self, prefix): print("CREATING TRAINING DATA...") currentDir = os.getcwd() os.chdir(self.directory) p = subprocess.Popen(["tesseract", prefix + ".tiff", prefix, "nobatch", "box.train"], stdout=subprocess.PIPE, stderr=subprocess.PIPE) returnValue = p.communicate()[1] returnValue = returnValue.decode("utf-8", errors='ignore') if "Empty page!!" in returnValue: os.chdir(self.directory) subprocess.call(["tesseract", "-psm", "7", prefix + ".tiff", prefix, "nobatch", "box.train"]) os.chdir(currentDir) def extractUnicode(self): currentDir = os.getcwd() print("EXTRACTING UNICODE...") boxList = self.getBoxFileList() boxArr = boxList.split(" ") boxArr.insert(0, "unicharset_extractor") boxArr = [i for i in boxArr if i != ''] os.chdir(self.directory) p = subprocess.Popen(boxArr) p.wait() os.chdir(currentDir) def createFontFile(self): currentDir = os.getcwd() os.chdir(self.directory) fname = self.directory + "/font_properties" with open(fname, 'w') as fout: fout.write(self.fontName + " 0 0 0 0 0") os.chdir(currentDir) def runShapeClustering(self): print("RUNNING SHAPE CLUSTERING...") # shapeclustering -F font_properties -U unicharset eng.captchaFont.exp0.tr... self.getTrainingFileList() shapeCommand = self.trainingList.split(" ") shapeCommand.insert(0, "shapeclustering") shapeCommand.insert(1, "-F") shapeCommand.insert(2, "font_properties") shapeCommand.insert(3, "-U") shapeCommand.insert(4, "unicharset") shapeCommand = [i for i in shapeCommand if i != ''] currentDir = os.getcwd() os.chdir(self.directory) p = subprocess.Popen(shapeCommand) p.wait() os.chdir(currentDir) def runMfTraining(self): # mftraining -F font_properties -U unicharset eng.captchaFont.exp0.tr... print("RUNNING MF CLUSTERING...") self.getTrainingFileList() mfCommand = self.trainingList.split(" ") mfCommand.insert(0, "mftraining") mfCommand.insert(1, "-F") mfCommand.insert(2, "font_properties") mfCommand.insert(3, "-U") mfCommand.insert(4, "unicharset") mfCommand = [i for i in mfCommand if i != ''] currentDir = os.getcwd() os.chdir(self.directory) p = subprocess.Popen(mfCommand) p.wait() os.chdir(currentDir) def runCnTraining(self): # cntraining -F font_properties -U unicharset eng.captchaFont.exp0.tr... print("RUNNING MF CLUSTERING...") self.getTrainingFileList() cnCommand = self.trainingList.split(" ") cnCommand.insert(0, "cntraining") cnCommand.insert(1, "-F") cnCommand.insert(2, "font_properties") cnCommand.insert(3, "-U") cnCommand.insert(4, "unicharset") cnCommand = [i for i in cnCommand if i != ''] currentDir = os.getcwd() os.chdir(self.directory) p = subprocess.Popen(cnCommand) p.wait() os.chdir(currentDir) def createTessData(self): print("CREATING TESS DATA...") # Rename all files and run combine_tessdata <language>. currentDir = os.getcwd() os.chdir(self.directory) os.rename("unicharset", self.languageName + ".unicharset") os.rename("shapetable", self.languageName + ".shapetable") os.rename("inttemp", self.languageName + ".inttemp") os.rename("normproto", self.languageName + ".normproto") os.rename("pffmtable", self.languageName + ".pffmtable") p = subprocess.Popen(["combine_tessdata", self.languageName + "."]) p.wait() os.chdir(currentDir) def getBoxFileList(self): if self.boxList is not None: return self.boxList self.boxList = "" files = os.listdir(self.directory) commandString = "unicharset_extractor" filesFound = False for fileName in files: if fileName.endswith(".box"): filesFound = True self.boxList += " " + fileName if not filesFound: self.boxList = None return self.boxList # Retrieve a list of created training files, caches # the list, so this only needs to be done once. def getTrainingFileList(self): if self.trainingList is not None: return self.trainingList self.trainingList = "" files = os.listdir(self.directory) commandString = "unicharset_extractor" filesFound = False for fileName in files: if fileName.endswith(".tr"): filesFound = True self.trainingList += " " + fileName if not filesFound: self.trainingList = None return self.trainingList if __name__ == '__main__': trainer = TesseractTrainer() trainer.runAll()
你需要动手设置的只有三个变量。
Tesseract 用三个字母的语言缩写代码表示识别的语言种类。可能大多数情况下,你都会用”eng“表示英语(English)。
表示你选择的字体名称,可以是任意名称,但必须是一个不包含空格的单词。
表示包含所有图片和 .box 文件的目录。建议你使用文件夹的绝对路径,但是如果你使用相对路径,可能需要以Python 代码运行的目录位置为原点。如果你使用绝对路径,就可以在电脑的任意位置运行代码了。 让我们再看看runAll 里每个函数的用法。
createFontFile 创建了一个 font_properties 文件,让 Tesseract 知道我们要创建的新字体:
captchaFont 0 0 0 0 0 这个文件包括字体的名称,后面跟着若干 1 和 0,分别表示应该使用斜体、加粗或其他版本的字体(用这些属性训练字体是一个很好玩儿的练习)。
cleanImages 首先创建所有样本图片的高对比度版本,然后转换成灰度图,并进行一些清理,让 Tesseract 更容易读取图片文件。如果你要处理的验证码图片上面有一些很容易过滤掉的噪点,那么你可以在这里增加一些步骤来处理它们。
renameFiles 把所有的图片文件和 .box 文件的文件名改变成 Tesseract 需要的形式(fileNumber 是文件序号,用来区别每个文件):
<languageName>.<fontName>.exp<fileNumber>.box <languageName>,<fontName>.exp<fileNumber>.tiff extractUnicode 函数会检查所有已创建的 .box 文件,确定要训练的字符集范围。抽取出的 Unicode 会告诉你一共找到了多少个不重复的字符,这也是一个查询字符的好方法,如果你漏了字符可以用这个结果快速排查。
之后的三个函数,runShapeClustering、runMfTraining 和 runCtTraining 分别用来创建文件 shapetable、pfftable 和 normproto。它们会生成每个字符的几何和形状信息,也为 Tesseract 提供计算字符若干可能结果的概率统计信息。
最后,Tesseract 会用之前设置的语言名称对数据文件夹编译出的每个文件进行重命名(例如:shapetable 被重命名为 eng.shapetable),然后把所有的文件编译到最终的训练文件 eng.traineddata 中。
你需要动手完成的唯一步骤,就是用下面的 Linux 和 Mac 命令行把刚刚创建的 eng-traineddata 文件复制到 tessdata 文件夹里,Windows 系统类似:
cp /path/to/data/eng.traineddata $TESSDATA_PREFIX/tessdata 经过这些步骤之后,你就可以用这些 Tesseract 训练过的验证码来识别新图片了。
评论已关闭。





