符号表是一种典型的ADT,它提供了操作键值对的方法: put(插入、insert)、search、delete操作,这一节将会给出两种初级的符号表: 无序链表中的顺序查找、基于有序数组二分查找的有序符号表。
在某些实现中我们认为保持键的有序性并大大扩展它的API是很有用。例如键是时间,你可能会对最早的或是最晚的或者给定时间段内的所有键感兴趣。在大多数情况下这些额外的操作只需要在数据结构上增加一些信息及少量代码即可实现,如下定义的一些API便支持一般的动态集合上顺序统计操作的数据结构(所谓第i个顺序统计量是该集合中第i小或大的元素)。
在一个给定不变的集合中选择第i个顺序统计量的问题,这种被称为选择问题。它可以在O(lgn)时间内利用堆排序或者合并排序对数据进行排序后再取第i个元素,或者基于快速排序的确定性划分算法在O(n)时间内取第i个元素。由此引申出了一个中位数的查找问题(中位数: 集合元素按大小顺序排序后其中间的位置的数,集合大小为奇数时,中位数唯一,位于中间;大小为偶数时,存在两个中位数,取其平均值即可)。对于集合固定的中位数查找只需要利用select操作找到中间的数即可,对于两个有序数组(长度一致或者不一致均可以)的中位数查找可以用分治法(每次可去除一半的元素)。
如果集合元素是动态变化呢,可以设计一个含最大堆和最小堆的数据类型,它能够在对数时间内插入元素或删除元素,常数时间内找到中位数。那么选择问题呢? 这里就用到了有序符号表的实现来支持这些动态顺序统计问题,它们能保证元素的选择、排名、范围查找都可以在对数时间内确定。
如图为有序符号表的API定义:


有序操作说明:
和优先队列一样,我们可以查询和删除集合中的最大和最小键
对于给定的键,向下取整操作即找出小于或等于该键的最大键,向上取整操作即找出大于或等于该键的最小键
选择问题计是查找出集合中的第i小关键字(即找出排名为i的键);排名问题是确定当前键的顺序位置
基于二分查找的有序符号表实现的核心操作是rank方法,它返回表中小于给定键的数量或者是应该插入的位置(范围:0-N)。它保留了以下性质:
可以知道循环结束时low的值正好等于表中小于被查找的键的数量,代码如下:
public int rank(Key key){ int low=0,high=N-1; while(low<=high){ int mid=low+ (high-low)/2; int cmp=key.compareTo(keys[mid]); if(cmp<0) high=mid-1; else if(cmp>0) low=mid+1; else return mid; } return low; }
其他的操作如get、put方法均利用rank方法找到该键的位置或者查找未命中的位置,完整的具体实现如下:
package algo.search; import java.util.NoSuchElementException; import com.stdlib.In; import com.stdlib.StdIn; import com.stdlib.StdOut; import algo.basic.LinkedQueue; public class BinSearchST<Key extends Comparable<Key>,Value> { private static final int INIT_CAPACITY=2; private Key[] keys; private Value[] vals; private int N; //键值对个数 public BinSearchST(int capacity) { keys=(Key[]) new Comparable[capacity]; vals=(Value[]) new Object[capacity]; N=0; } public BinSearchST(){ this(INIT_CAPACITY); } public int size(){ return N; } public boolean isEmpty(){ return N==0; } public boolean contains(Key key){ return get(key)!=null; } /** * 如果符号表为空,返回null * 找到key的排名rank,如果位置合法并且给定的键值与对应位置的键值相等,返回对应的实值 * 否则返回null */ public Value get(Key key){ if(isEmpty()) return null; int pos=rank(key); if(pos<N && key.compareTo(keys[pos])==0) return vals[pos]; return null; } /** * 插入键值对,查找键找到就更新值,后面的元素整体右移结点个数加1 */ public void put(Key key,Value val){ if(val==null){ delete(key); return; } /*小于key的键的数量,*/ int i=rank(key); /*如果键在表中,更新键值对*/ if(i<N&&key.compareTo(keys[i])==0){ vals[i]=val; return ; } /*元素个数已满,等于容量大小*/ if(N==keys.length) resize(2*keys.length); for(int j=N;j>i;j--){ keys[j]=keys[j-1]; vals[j]=vals[j-1]; } keys[i]=key; vals[i]=val; N++; assert check(); } public void delete(Key key){ if(isEmpty()) return; int i=rank(key); if(i==N ||key.compareTo(keys[i])!=0){ return ; } for(int j=i;j<N-1;j++){ keys[j]=keys[j+1]; vals[j]=vals[j+1]; } N--; keys[N]=null; vals[N]=null; if(N>=0&& N==keys.length/4) resize(keys.length/2); assert(check()); } /********************************* * 有序性操作: * 最大键、最小键(删除最大、最小键) * 对于给定的键,向下取整(floor)操作: 找出小于等于该键的最大键 * 对于给定的键,向上取整(ceiling)操作: 找出大于等于该键的最小键 * 排名操作(rank): 找出小于指定键的键的数量 * 选择操作(select): 找出排名为k的键 * 范围查找: 在两个给定的键之间有多少键,分别是哪些 *********************************/ /** * rank采用了类似于二分查找的操作,rank返回的范围是0..N * 如果表中存在该键,rank()应该返回该键的位置,也就是表中小于该键的数量 * 如果不存在该键,rank()还是应该返回表中小于它的键的数量 */ public int rank(Key key){ int low=0,high=N-1; while(low<=high){ int mid=low+ (high-low)/2; int cmp=key.compareTo(keys[mid]); if(cmp<0) high=mid-1; else if(cmp>0) low=mid+1; else return mid; } return low; } public Key select(int i){ if(i<0 || i>=N) return null; return keys[i]; } public Key min(){ if(isEmpty()) return null; return keys[0]; } public Key max(){ if(isEmpty()) return null; return keys[N-1]; } /** * floor、ceiling、rank()-最多是对数级别的操作 * rank()- 找到键的排名 * select(): 取排名为k的键(O(1)复杂度) * @param key * @return */ /*取大于或等于它的最小键,要么是当前的键或者应该插入的位置()*/ public Key ceiling(Key key){ int i=rank(key); if(i==N) return null; return keys[i]; } /*取小于或等于该键的最大键*/ public Key floor(Key key){ int i=rank(key); if(i<N && key.compareTo(keys[i])==0) return keys[i]; if(i==0) return null; //取小于首元素的最大键,必然是null return keys[i-1]; //常规是小于当前键的最大键 } public void deleteMin(){ if(isEmpty()) throw new NoSuchElementException("符号表下溢错误!"); delete(min()); } public void deleteMax(){ if(isEmpty()) throw new NoSuchElementException("符号表下溢错误!"); delete(max()); } /*[low..high]的键已排好序*/ public int size(Key low,Key high){ if(low.compareTo(high)>0) return 0; if(contains(high)) return rank(high)-rank(low)+1; else return rank(high)-rank(low); } /*表中的所有键的集合,已排序*/ public Iterable<Key> keys(){ return keys(min(),max()); } /*[low..high]之间的所有键,已排序*/ public Iterable<Key> keys(Key lo,Key hi){ LinkedQueue<Key> queue=new LinkedQueue<Key>(); if(lo==null&&hi==null) return queue; if(lo==null|| hi==null) throw new NoSuchElementException("某键不存在"); if(lo.compareTo(hi)>0) return queue; for(int i=rank(lo);i<rank(hi);i++) queue.enqueue(keys[i]); if(contains(hi)) queue.enqueue(keys[rank(hi)]); return queue; } private void resize(int capacity){ assert capacity>=N; Key[] keysTemp=(Key[]) new Comparable[capacity]; Value[] valsTemp=(Value[]) new Object[capacity]; for(int i=0;i<N;i++){ keysTemp[i]=keys[i]; valsTemp[i]=vals[i]; } keys=keysTemp; vals=valsTemp; } /********************************* * 检查内部不变式 *********************************/ private boolean check(){ return isSorted()&& rankCheck(); } private boolean isSorted(){ for(int i=1;i<N;i++) if(keys[i].compareTo(keys[i-1])<0) return false; return true; } //检查选择第i个位置的键值对应的位置是否为i-rank(select(i))=i private boolean rankCheck(){ for(int i=0;i<size();i++) if(i!=rank(select(i))) return false; for(int i=0;i<size();i++) if(keys[i].compareTo(select(rank(keys[i])))!=0) return false; return true; } public static void test(String filename){ BinSearchST<String,Integer> st=new BinSearchST<String,Integer>(); In input=new In(filename); int i=0; while(!input.isEmpty()){ String key=input.readString(); st.put(key,i); i++; } for(String s: st.keys()){ StdOut.println(s+ " "+st.get(s)); } String key=st.floor("F"); StdOut.println("E的向下取整键值对(key-val): "+key+" "+st.get(key)); StdOut.println(st.rank("E")+" "+st.select(1)); key=st.ceiling("F"); StdOut.println("E的向上取整键值对(key-val): "+key+" "+st.get(key)); StdOut.println(st.size("E","P")); for(String s: st.keys("E","P")){ StdOut.println(s+ " "+st.get(s)); } } public static void computeGPA(){ BinSearchST<String,Double> st=new BinSearchST<String,Double>(); st.put("A+", 4.33); st.put("A",4.00); st.put("A-", 3.67); st.put("B+",3.33); st.put("B",3.00); st.put("B-",2.67); st.put("C+",2.33); st.put("C",2.00); st.put("C-",1.67); st.put("D",1.00); st.put("F",0.00); int n=0; double total=0.0; for(n=0;!StdIn.isEmpty();n++){ String grade=StdIn.readString(); total +=st.get(grade); } double gpa=total/n; StdOut.println("GPA = "+ gpa); } public static void main(String[] args) { //test("tiny.txt"); computeGPA(); } }
根据二叉查找树的定义,有左子树结点值小于或等于根结点值,右子树结点值大于等于根结点值的性质,因而对BST进行中序遍历,能够得到一个非递减的有序序列。因而进行BST的相关操作时必须维护它的有序性质
为了实现有序的操作,可以BST的结点内部定义一个变量N,统计以该结点为根的子树的结点总数。结点定义如下:
/*和二分查找定义结点总数N的方式不同*/ private class Node{ private Key key; private Value val; private Node left,right; private int N; //以该结点为根的子树中结点的总数 /*结点计数器的效果是简化了很多有序性操作的实现*/ public Node(Key key,Value val,int N){ this.key=key; this.val=val; this.N=N; } }
/*在二叉查找树中查找键值对应的实值*/ public Value get(Key key){ Node x=root; while(x!=null){ int cmp=key.compareTo(x.key); if(cmp<0) x=x.left; else if(cmp>0) x=x.right; else return x.val; } return null; }
对于插入操作,即先检查这个元素是否存在,存在更新值,不存在插入新结点。它的递归实现和非递归实现都比较简单(非递归插入维护结点计数器略微有点麻烦),如下为递归插入的代码:
对于查找操作,思路很简单: 先与根结点进行比较,如果相同查找结束;否则根据比较结果,被查找的结点较小沿左子树查找,较大沿右子树查找。对于一个未命中的查找返回null。实现如下:
/** * 递归插入思路: * 如果树是空的,就返回一个含该键值对的新节点 * 如果被查找的键小于根结点的的键,递归在左子树中插入 * 如果被查找的键小于根结点的的键,递归在右子树中插入 * 注意: 递归地在路径上将每个结点中的计数器值加1 * 非递归的思路: 实现也不复杂,但更新结点计数器的方法比较复杂 */ private Node put(Node x,Key key,Value val){ if(x==null) return new Node(key,val,1); int cmp=key.compareTo(x.key); if(cmp<0) x.left=put(x.left,key,val); else if(cmp>0) x.right=put(x.right,key,val); else x.val=val; x.N=size(x.left)+size(x.right)+1; //更新结点的计数(递归方式) return x; }
对于删除操作,要想删除树中的某个结点,还必须保证BST树的排序不会丢失。思路如下:
对于删除最大值或最小值操作,只需要一直沿左或右侧遍历直到遇见第一个空链接位置然后返回另外一侧的链接。这三个删除操作的Java实现如下:
public void deleteMin(){ if (isEmpty()) throw new NoSuchElementException("符号表为空"); root=deleteMin(root); } /** * 不断深入根结点的左子树中直到遇到一个空链接 * 然后把指向该节点的链接指向该节点的右子树(返回它的右链接即可) * 并递归更新在新节点到根结点的路径上的所有结点的计数器的值 */ private Node deleteMin(Node x){ if(x.left==null) return x.right; x.left=deleteMin(x.left); x.N=size(x.left)+size(x.right)+1; //更新结点的计数(递归方式) return x; } public void deleteMax(){ if (isEmpty()) throw new NoSuchElementException("符号表为空"); root=deleteMax(root); } /** * 不断深入根结点的右子树中直到遇到一个空链接 * 然后把指向该节点的链接指向该节点的左子树(返回它的左链接即可) * 并递归更新在新节点到根结点的路径上的所有结点的计数器的值 */ private Node deleteMax(Node x){ if(x.right==null) return x.left; x.right=deleteMax(x.right); x.N=size(x.left)+size(x.right)+1; //更新结点的计数(递归方式) return x; } public void delete(Key key){ root=delete(root,key); } /** * 删除结点x用它的后继结点填补它的位置-一般是右子树的最小结点 */ private Node delete(Node x,Key key){ if(x==null) return null; int cmp=key.compareTo(x.key); if(cmp>0) x.left=delete(x.left,key); else if(cmp<0) x.right=delete(x.right,key); else { if(x.right==null) return x.left; if(x.left==null) return x.right; Node t=x; //暂存当前键的结点 x=min(t.right); //取右子树的最小结点 x.right=deleteMin(t.right); //删除最小节点的有节点 x.left=t.left; //原来的左孩子指向新结点的左链接 } x.N=size(x.left)+size(x.right)+1; //更新结点的计数(递归方式) return x; }
A. 选择操作
select操作和快速排序中的数组划分操作很类似,我们在BST中的每个结点维护结点计数器变量N就是来支持此操作的。找到排名为k的键的思路如下:
代码实现如下:
/*返回排名为k的键值*/ public Key select(int k){ if(k <0 || k >=size()) return null; //排名0-N-1 return select(k,root).key; } private Node select(int k,Node x){ if(x==null) return null; int t=size(x.left); if(t>k) return select(k,x.left); else if(t<k) return select(k-t-1,x.right); else return x; }
B. 排名操作
rank操作返回给定键的排名(即以x为根结点的子树中小于key的键的数量),它的实现和select类似。思路如下:
代码实现如下:
public int rank(Key key){ return rank(key,root); } /** * 排名操作 * 返回以x为根结点的子树中小于key的键的数量 * 如果给定的键与根结点键相等,返回左子树中结点的个数 * 小于根结点,返回该键在左子树中的排名 * 大于根结点,返回该键在右子树的排名+左子树结点个数+1 */ private int rank(Key key,Node x){ if(x==null) return 0; int cmp=key.compareTo(x.key); if(cmp<0) return rank(key,x.left); else if(cmp>0) return 1+size(x.left)+rank(key,x.right); else return size(x.left); }
C. 取整操作
向下取整操作的思路:
向上取整操作的思路:
代码实现如下:
public Key floor(Key key){ Node x=floor(root,key); if(x==null) return null; return x.key; } private Node floor(Node x,Key key){ if(x==null) return null; int cmp=key.compareTo(x.key); if(cmp==0) return x; else if(cmp<0) return floor(x.left,key); else { Node t=floor(x.right,key); if(t==null) return x; else return t; } } public Key ceiling(Key key){ Node x=ceiling(root,key); if(x==null) return null; return x.key; } private Node ceiling(Node x,Key key){ if(x==null) return null; int cmp=key.compareTo(x.key); if(cmp==0) return x; else if(cmp>0) return ceiling(x.right,key); else { Node t=ceiling(x.left,key); if(t==null) return x; else return t; } }
D. 范围查找及统计
范围查找思路很简单,通过比较和两个给定键的大小,将所有落在特定范围内的键加入队列中并跳过那些不可能含有查找键的子树。代码实现如下:
public Iterable<Key> keys(Key lo,Key hi){ LinkedQueue<Key> queue=new LinkedQueue<Key>(); keys(root,queue,lo,hi); return queue; } private void keys(Node x,LinkedQueue<Key> queue,Key lo,Key hi){ if(x==null) return; int cmplo=lo.compareTo(x.key); int cmphi=hi.compareTo(x.key); if(cmplo<0) keys(x.left,queue,lo,hi); if(cmplo <=0 && cmphi >=0) queue.enqueue(x.key); if(cmphi>0) keys(x.right,queue,lo,hi); } public int size(Key lo,Key hi){ if(lo.compareTo(hi)>0) return 0; if(contains(hi)) return rank(hi)-rank(lo)+1; else return rank(hi)-rank(lo); }
可以看到所有操作在最坏情况下所需的时间都和树的高度成正比。如果BST是一个只有左(右)孩子的单支树,它的高度为结点的个数,在这种情形下BST的性能是非常糟糕的。因而为了避免树的高度增长过高,我们可以构造随机化BST(J.Robson证明随机键构造的二叉查找树的平均高度为树中结点数的对数级别)或者增加一些信息维护树的平衡,如AVL树、红黑树、伸展树等。
二叉查找树中结点和结构的定义如下:
/*二叉查找树的结点定义*/ typedef struct bst_node { void *item; struct bst_node *left; struct bst_node *right; } bst_node_t; /*二叉查找树的结构定义*/ typedef struct bst { bst_node_t *root; int n; int (*comp)(const void *,const void *); } bst_t;
这里实现的操作基本上都是非递归的版本,不过并没有实现各种有序性操作(通过在二叉树的结点中定义统计以该节点为根的子树结点总数)。
#include <stdlib.h> #include "bst.h" /** * bst.c - Binary Search Tree Implementation * */ /*为二叉查找树分配内存,comp是一个比较两元素大小的函数指针*/ bst_t *bst_alloc(int (*comp)(const void *,const void *)){ bst_t *t=malloc(sizeof(bst_t)); t->root=NULL; t->n =0; t->comp=comp; return t; } /*释放二叉查找树的内存*/ void bst_free(bst_t *t) { bst_node_t *cur; bst_node_t **stack; //维护一个指向bst_node结点的的指针数组栈 /** * 释放每个结点的内存: 通过VRL的访问方式,根结点首先入栈 * 如果栈不空,结点出栈,若结点的孩子不空,子结点入栈(先右后左),再释放当前根结点空间 * 只要栈不空采用DFS遍历的方式重复上面的操作 * 和VRL遍历方式类似 */ if(t->root){ //根结点不空 //分配n个指针元素的内存 stack=malloc((t->n) * sizeof(bst_node_t *)); stack[0]= t->root; //根结点入栈 int top=1; while(top) { cur=stack[--top]; //出栈 if(cur->right){ //以先右后左方式入栈保存子结点,出栈则以先左后右 stack[top++]=cur->right; } if(cur->left){ stack[top++]=cur->left; } free(cur); } free(stack); //注意不释放栈内存则产生内存泄露 } free(t); } /** * bst_insert(): 要求插入的元素项的键不能和树中元素键相同,键独一无二 * 思路: 首先检查该元素是否已经存在,若查找成功,直接返回该位置 * 否则查找不成功,把新元素插入到查找停止的地方 */ void *bst_insert(bst_t *t,void *item) { int (*comp)(const void *,const void *); bst_node_t *prev=NULL; //保存待插入结点的父结点 int cmp_res; if(t->root){ bst_node_t *cur=t->root; comp=t->comp; while(cur){ cmp_res=comp(item,cur->item); if(cmp_res < 0){ prev=cur; cur=cur->left; } else if(cmp_res > 0) { prev=cur; cur=cur->right; } else return cur->item; //找到了并返回关键字item,不再插入 } } /*构造新结点*/ bst_node_t *node=malloc(sizeof(bst_node_t)); node->left=node->right=NULL; node->item=item; if(!prev){ t->root=node; } else { cmp_res=comp(item,prev->item); if(cmp_res < 0){ prev->left=node; } else { prev->right=node; } } t->n++; return NULL;//插入成功返回NULL } /** * bst_find(): 查找树中的某个关键字 * 思路: 先与根结点比较,若相同则查找结束 * 否则根据比较结果,沿着左子树或右子树向下继续查找 * 如果没有找到,返回NULL * 注: 这里的item是指关键字的值,而非结点 */ void *bst_find(bst_t *t ,void *item){ bst_node_t *cur; int (*comp)(const void *,const void *); cur=t->root; comp=t->comp; while(cur){ int cmp_res=comp(item,cur->item); if(cmp_res < 0){ cur=cur->left; } else if(cmp_res > 0) { cur=cur->right; } else return cur->item; //找到了并返回关键字item } return NULL; } /*返回二叉查找树中的含最小键值的结点*/ void *bst_find_min(bst_t *t) { bst_node_t *cur; if(t->root){ cur=t->root; while(cur->left){ cur=cur->left; } return cur->item; } else { return NULL; } } /** * bst_delete : 删除树中的某个结点,还必须保证BST树的排序不会丢失 * (1) 被删除结点是叶结点,直接删除,不会影响BST的性质 * (2) 若结点z只有一颗左子树或者右子树,让z的子树成为z父结点的子树,替代z位置 * (3) 若结点有两个子树,令它的直接后继(直接前驱)替代z, * 再从BST树中删除该直接后继(直接前驱),这样转换成了前两个情况 */ void *bst_delete(bst_t *t,void *item) { bst_node_t *cur,*prev; int (*comp)(const void *,const void *); prev=NULL; if(t->root){ cur=t->root; comp=t->comp; while(cur){ int cmp_res=comp(item,cur->item); if(cmp_res < 0){ prev=cur; cur=cur->left; } else if(cmp_res > 0) { prev=cur; cur=cur->right; } else break; //找到了并返回关键字item } } else { return NULL; } /*前两个条件可表示三种情形*/ if(!cur->left){ //左孩子为空,右孩子代替它 if(!prev){ t->root=cur->right; } else if(cur==prev->left) { prev->left=cur->right; } else { prev->right=cur->right; } } else if(!cur->right){ //右孩子为空,左孩子代替它 if(!prev){ t->root=cur->left; } else if(cur==prev->left) { prev->left=cur->left; } else { prev->right=cur->left; } } else { //找到当前结点右子树的最左孩子 bst_node_t *prev_cur=cur; bst_node_t *cur_cur=cur->right; while(cur_cur->left){ prev_cur=cur_cur; cur_cur=cur_cur->left; } /*更新cur结点的父亲结点prev的孩子链接信息*/ if(!prev){ t->root=cur_cur; } else if(cur==prev->left){ prev->left=cur_cur; } else { prev->right=cur_cur; } /*更新cur_cur的左右孩子链接信息*/ if(prev_cur!=cur){ //最左孩子的父结点不是要删除的结点, cur_cur不是cur的右孩子 prev_cur->left=cur_cur->right; cur_cur->right=cur->right; } cur_cur->left=cur->left; } void *res_item=cur->item; free(cur); t->n--; return res_item; } /*删除BST树中最小的键值结点*/ void *bst_delete_min(bst_t *t){ bst_node_t *cur,*prev; prev=NULL; if(t->root){ cur=t->root; while(cur->left){ prev=cur; cur=cur->left; } } else { return NULL; } if(!prev){ t->root=cur->right; } else { prev->left=cur->right; } void *res_item=cur->item; free(cur); t->n--; return res_item; }
AVL树定义任意结点的左右子树高度差的绝对值不超过1,定义结点左子树与右子树的高度差为该结点的平衡因子(BF)。
AVL树保证平衡的基本思路是: 每当在树中插入或删除一个结点时,首先需要检查其路径上的结点是否因为这次操作而导致了不平衡,由于只有从根结点到插入点的路径上的每个结点可能改变平衡状态。因而只要找到插入路径上离插入结点最近的平衡银子绝对值大于1的结点X,再对以结点X为根的子树,在保持BST有序特性的前提下,调整各结点的位置关系,使之重新达到平衡。
我们可以根据平衡被破坏时X的左右两棵子树的高度差为2分为四种情况,假设结点X为cur结点(参考STL源码剖析的5.1小节)
方法很简单: A子树提上一层,C子树下降一层,可以理解为把k1向上提起,使k2自动下滑,并使B子树挂到k2的左侧,保持了平衡,如图: 代码实现如下:
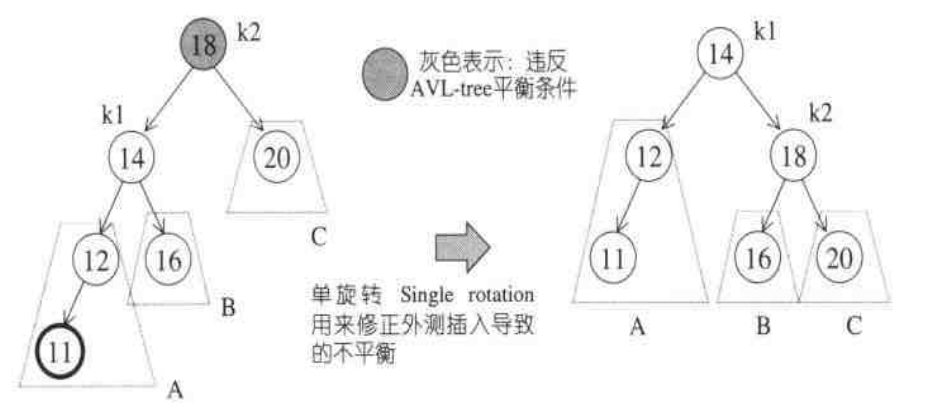
/*省去其他细节,比如实际函数里面可能含有一个avl的数据结构avl_t */ void single_rotate_right(avl_node_t *cur){ avl_node_t *next=cur->left; cur->left=next->right; next->right=cur; cur=next; }
同上,代码实现如下:
void single_rotate_left(avl_node_t *cur){ avl_node_t *next=cur->right; cur->right=next->left; next->left=cur; cur=next; }
思路: (以k2为新的根结点,使得k1必须为左子树,k3必须为右子树)先把k2提上去,然后k1自然下滑(左单旋转),然后再把k2提上去,k3自然下滑,注意保持左右子树有序的性质。如图: 代码实现如下:
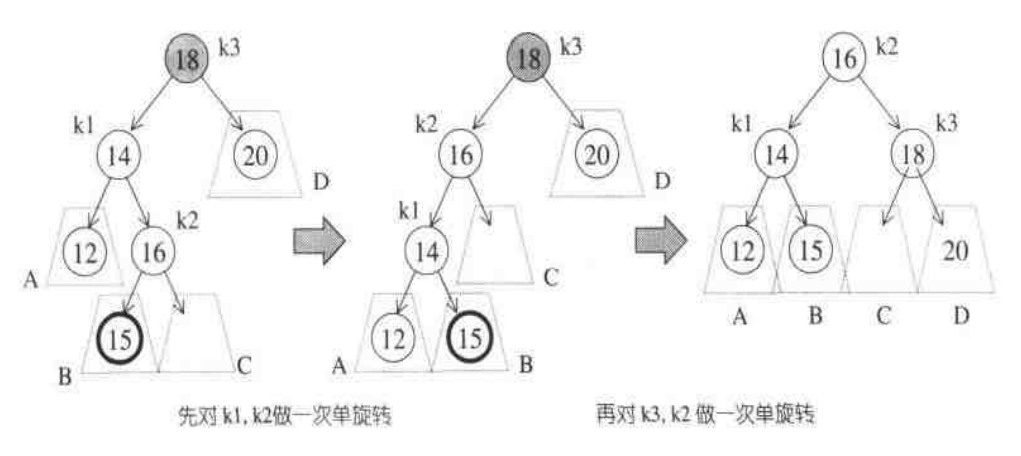
void double_rotate_right_left(avl_node_t *cur){ avl_node_t *next=cur->left; avl_node_t *last=next->right; next->right=last->left; last->left=next; next=last; //以上为左单旋转 cur->left=next->right; next->right=cur; cur=next; //这3行为右单旋转 }
同上面的思路,代码不再赘述。
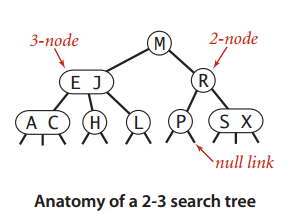
一颗2-3查找树或为一棵空树,或由以下节点组成:
我们把指向一颗空树的链接称为空链接,一般地完美平衡的2-3查找树中的所有空链接到根结点的距离都应该是相同的,如图所示:
所有叶子结点在树的同一层,因此树总是高度平衡的。注意到在除了提供符号表基本的查找、插入、删除操作外,由于BST是有序的,它同样支持有序操作,如选择、排名、范围查找、向上或向下调整。
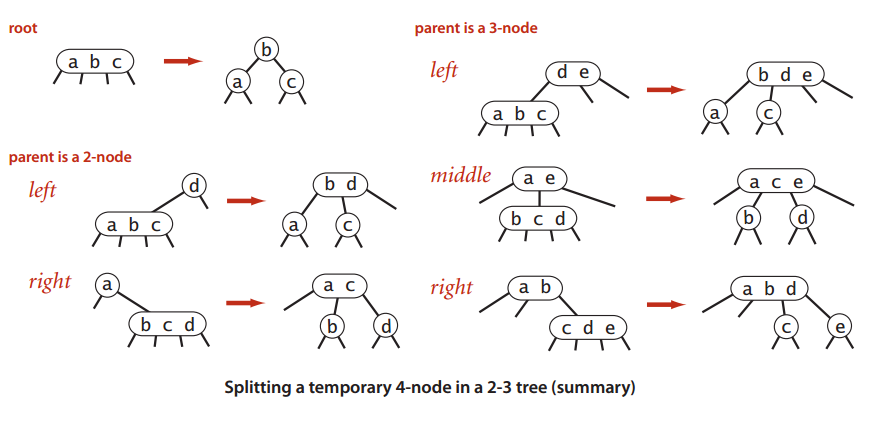
2-3树的查找算法和二叉查找树的算法基本类似,这里不再详述。为了在树中插入一个新结点,我们可能先进行一次未命中的查找,然后把新结点挂在树的底部。对于插入我们要讨论以下情形:
这种情形类似于在2-结点中插入新键。若未命中的查找结束于一个2-结点,只需要把2-结点替换成3-结点即可,如图:
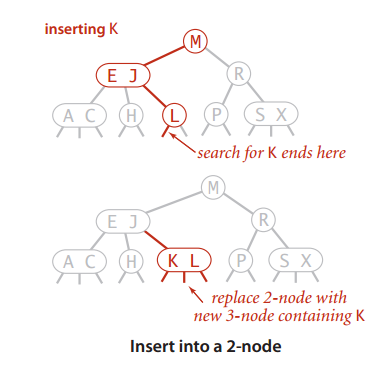
为了维持树的完美平衡需要为新键腾出空间,假想一个4-结点然后把其中键移动值原来的父结点中,新父结点中的原中键左右两边的两个链接分别指向了两个新的2-结点。这种转换并不影响2-3树的主要性质- 插入后所有的叶子节点到根结点的距离是相同的。如图:
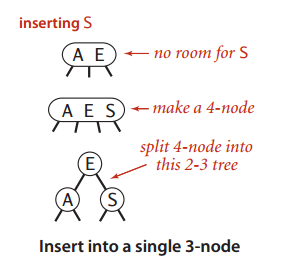
这种情形类似于 在一棵只含有一个3-结点的树中插入新键。为了将新键插入,先临时把新键存入结点中,变成一个4-结点,很容易把它转换成一个由3个2-结点组成的2-3树,其中根结点含有中键,另外两个分别持有3个键中的最大者和最小者。可以看出插入前后树的高度由0变成了1,例子很简单,但它说明了2-3树是如何生长的。 如图:
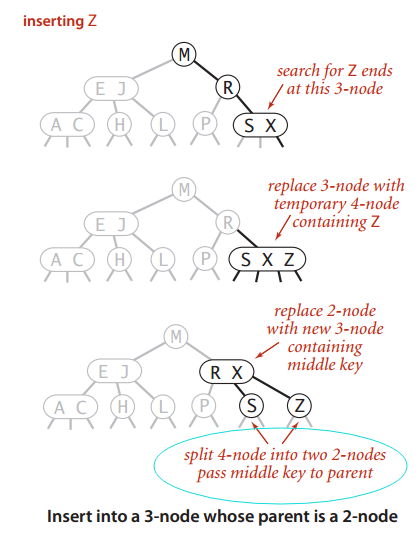
假设未命中的查找结束于一个3-结点,如情形3。先将中键插入它的父节点中,但父结点是3-结点,我们再利用中键构造一个新的临时4-结点,对父结点进行相同的变换,即分解父结点并把它的中键插入到它的父结点中取。推广到一般情况,我们就这样一直向上不断分解临时的4-结点并将中键插入更高层的父结点中,直到遇到一个2-结点并将它替换成一个不需要继续分解的3-结点或者到达3-结点的根。 如图:
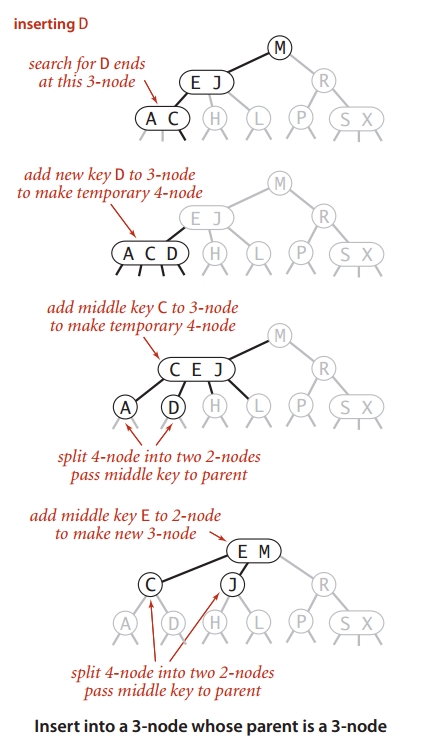
可以看到2-3树的插入算法只需要修改相关的结点和链接而不必修改或者检查树的其他部分。这种局部变换中变更的链接数不会超过一个很小的常数,操作结束后依然能保持任意的叶子结点到根结点的路径长度是相等的性质,即保持了树的完美平衡。
如图为在2-3树中分解为一个4-结点的情况汇总:
2-3树的分析和BST的分析大不相同,因为我们主要感兴趣的是最坏情况下的性能(我们无法控制用例以怎样的顺序输入,因此对最坏情况的分析是唯一能够提供性能保证的方法),而非一般情况(使用随机键模型分析预期的性能)。 如下两图分别为按升序的插入到树中、随机键构造的树:

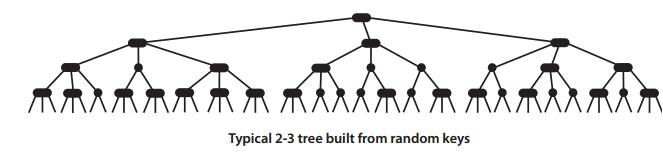
2-3树在最坏情况下任何查找、插入的成本都不会超过对数级别。经过实验了解到:
2-3-4树也可按照结点的度数来定义:
一般认为B-树是2-3树(阶为3的B-树)、2-3-4树(阶为4的B-树)的推广,它们均是通过操作结点的度数来维持平衡的。这里给出B树的具体定义,一棵m阶的B-树,或为空树或为满足下列特性的m叉树:
例如一个3阶的B-树,每个结点最多有3个链接、2个关键字,最少有2个链接、1个关键字;一个6阶的B-树,每个结点至少有3个至多有5个的链接(根结点除外,它可以只含有2个链接、1个关键字)。B树通常用作字典、数据检索系统的自平衡结构、文件系统,其大部分操作所需的磁盘存取次数与B-树的高度成正比。对于任意一颗含有n个关键字、高度为h的m阶B-树,它满足以下条件
即一个有8个关键的3阶B-树,高度范围为[2,3.17]
在进行B树的插入、删除时为了满足B-树中结点关键字个数的要求需要进行调整-分裂结点或移动结点,这是B-树操作正确实现的核心步骤,这其实和2-3树或者2-3-4树的插入类似,不再详述,有空可以自己实现一个
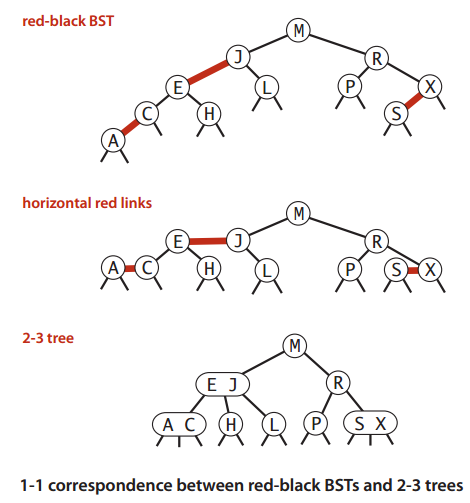
在Robert Sedegwick的算法书中说到,红黑二叉查找树的基本思想是用标准的二叉查找树和一些额外的信息(颜色)来表示2-3树。其中红色链接将两个2-结点链接起来表示一个3-结点,对于任意的2-3树我们都可用等价的二叉查找树来表示,这种树被称为红黑树。它是一种颇具历史并被广泛运用的平衡二叉查找树,能够保证在最坏情形下查找、插入、删除、求最值、选择、排序、范围查找等操作所需的时间是对数级别的
注意在RS的算法和CLRS的算法导论中红黑树的定义是有所不同的,但它们的意义是等价的。可以对比一下:
算法导论中的红黑树定义如下:
算法中的红黑树定义如下:
可以看到:
如下为红黑树和2-3树的一一对应关系:
这里的实现参考Robert Sedgewick的算法书,定义一个内部结点类,链接的颜色定义在Color变量中,有序性操作的实现需要定义子树中结点的总数N,如下所示:
private class Node { private Key key; private Value val; private Node left,right; private int N; //该子树的结点总数 private boolean color; //由其父结点指向它的链接的颜色 public Node(Key key, Value val, boolean color, int N) { this.key = key; this.val = val; this.color = color; this.N = N; } }
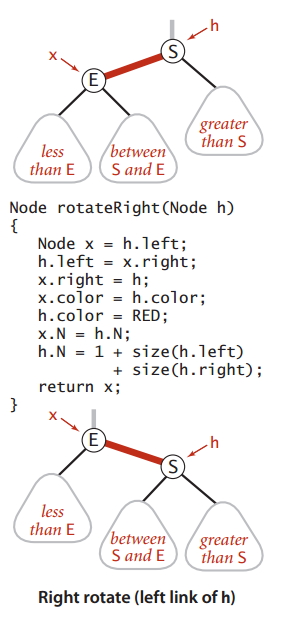
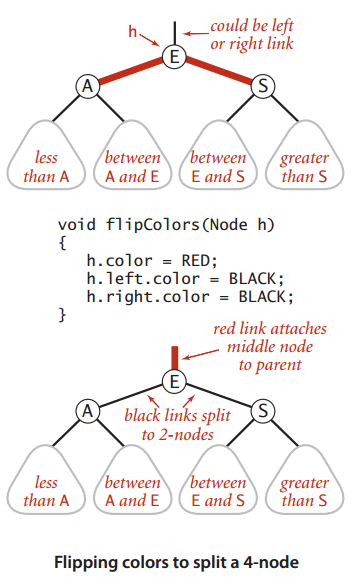
在插入新的键时我们使用旋转操作来保持红黑树的各种定义性质:有序性、完美黑色平衡性、不存在两条连续的红色链接和不存在红色的右链接。如下为旋转和颜色转换操作的处理情形:

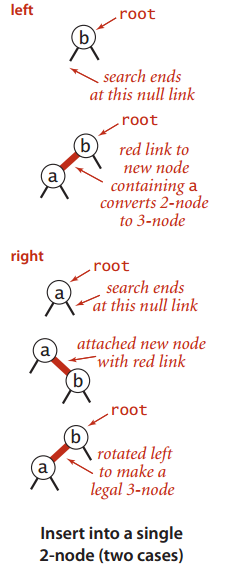
如下为插入操作的讨论
这种方法只需要讨论如果树只有一个2-结点该如何插入新键,即
如图所示
在树底部的2-结点插入新键操作和上面操作类似
这种方法同样我们只需要讨论如果树只有一个3-结点该如何插入新键,即
这样我们通过0,1,2次旋转以及颜色的变化的到了期望的结果,如图所示:
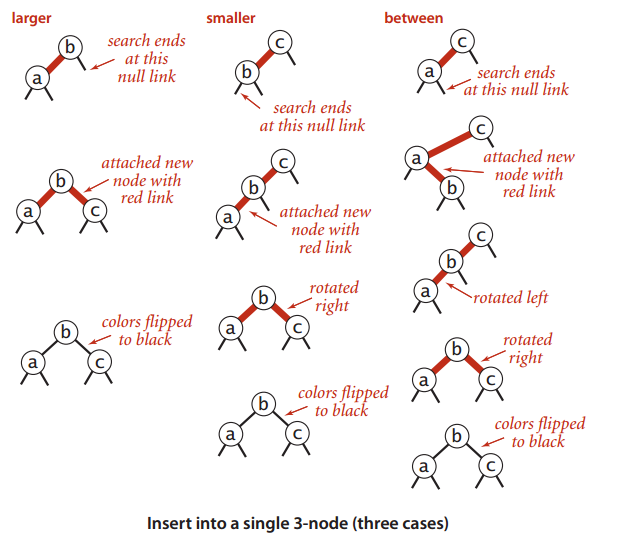
因而在树的底部的3-结点中插入一个新结点,它可能的位置如上面所讨论的情形类似。值得注意的是,当颜色发生转换时中结点的链接变红,可使得红色链接不断在树中向上传递,直至遇到一个2-结点或者根结点。
public class RedBlackBST<Key extends Comparable<Key>, Value> { private static final boolean RED=true; private static final boolean BLACK=false; private Node root; private class Node { private Key key; private Value val; private Node left,right; private int N; //该子树的结点总数 private boolean color; //由其父结点指向它的链接的颜色 public Node(Key key, Value val, boolean color, int N) { this.key = key; this.val = val; this.color = color; this.N = N; } } /*结点辅助函数*/ private boolean isRed(Node x){ if(x==null) return false; return (x.color==RED); } /** * 左旋转 * 若新增的红色结点会产生一个红色的右链接 * 只需要将插入结点的父结点旋转为红色左链接,修改颜色和结点总数 */ private Node rotateLeft(Node h){ Node x=h.right; h.right=x.left; x.left=h; x.color=h.color; h.color=RED; x.N=h.N; h.N=1+size(h.left)+size(h.right); return x; } /** * 右旋转 * 若新增的红色结点会产生一个红色的左链接(两个连续的红色左链接) * 使左链接lean向右侧 */ private Node rotateRight(Node h){ Node x=h.left; h.left=x.right; x.right=h; x.color=h.color; h.color=RED; x.N=h.N; h.N=1+size(h.left)+size(h.right); return x; } /** * 当左右链接均为红链接时 * 子结点的颜色由红变黑,父节点的颜色由黑变红 */ private void flipColors(Node h){ h.color=!h.color; h.left.color=!h.left.color; h.right.color=!h.right.color; } private int size(Node x){ if(x==null) return 0; return x.N; } public int size(){ return size(root); } public boolean isEmpty(){ return (root==null); } public Value get(Key key){ Node x=root; while(x!=null){ int cmp=key.compareTo(x.key); if(cmp<0) x=x.left; else if(cmp>0) x=x.right; else return x.val; } return null; } public boolean contains(Key key){ return get(key)!=null; } /*自底向上更新结点颜色,并始终保持根结点颜色是黑色*/ public void put(Key key,Value val){ root=put(root,key,val); root.color=BLACK; } /** * 树形调整操作: 旋转及改变颜色,重新令树保持平衡 */ private Node put(Node h,Key key,Value val){ if(h==null) return new Node(key,val,RED,1); /*查找到未命中结点的位置*/ int cmp = key.compareTo(h.key); if (cmp < 0) h.left = put(h.left, key, val); else if (cmp > 0) h.right = put(h.right, key, val); else h.val = val; /*修正任何右倾的链接,递归地自底向上判断h结点及其孩子结点的颜色*/ if(isRed(h.right)&& !isRed(h.left)) h=rotateLeft(h); if(isRed(h.left)&& isRed(h.left.left)) h=rotateRight(h); if(isRed(h.left)&& isRed(h.right)) flipColors(h); h.N=1+size(h.left)+size(h.right); return h; } }
红黑树中delete操作的实现比较复杂,工业界实现的代码量大概100行左右,可以参考下STL的红黑树实现
和典型的二叉查找树相比,一棵典型的红黑树的平衡性是很好的,大小为N的红黑树的高度不超过2lgN,使得它所有操作的运行时间都是对数级别的。
红黑树这种近乎完美的平衡性,在效率表现和实现复杂度上也保持相当的"平衡",所以运用很广,使得STL中的map和set均以RB-tree为底层机制,元素的自动排序效果很不错,map和set所开放的各种操作接口实际上是调用红黑树的各种操作行为而已,对比SGI的hash_map、hash_set是以散列表hash table作为底层机制,它不具有自动排序功能。
总结下来,我们已经实现了各种各样的符号表(字典),包括散列表。那么对于一些典型的应用程序,我们该使用符号表的哪种实现呢?
和二叉查找树相比,Hash-table的优点在于代码更简单,支持常数级别的插入和查找操作;key实现是无序的,并且无需比较;散列函数的计算可能复杂而且昂贵
二叉查找树相对于散列表的优点在于抽象结构更简单(无需设计散列函数),尽管一般的二叉查找树很实用,但它还是有一些缺点,如链接使用了大量的内存空间,若内存资源宝贵的话,建议使用开地址法的散列实现
如果通用的二叉查找树的平衡性变得很差,并引起性能急剧降低,基于一般的BST衍生出了很多保证对数性能或平衡性的结构,如随机化BST、AVL树、红黑树、跳跃表、伸展BST(splay生成树)、Treap
随机化BST对随机数生成器有要求,并试图避免花费太多时间生成随机位;AVL树是通过约束任意节点的左右子树的高度差来维护树的平衡,如果结点不平衡时可以借助4种旋转操作使树重新获得平衡;伸展BST是一种频繁访问小型关键字集合的应用,它的自调整形式会沿着结点到根的路径通过一系列的选择把该结点移到树根上去(为了使整个查找时间最小,被查频率高的条目应当处于靠近树根的位置)
红黑树是平衡性近乎完美的一种二叉查找树,通过旋转和颜色的调整保证最坏情况下的对数性能且它能够支持的操作更多(如排名、选择、排序和范围查找)。根据经验法则,大多数程序员的第一选择是散列表,在其他因素更重要时才会选择红黑树
跳跃表也是一种平衡的二叉树,扩充了一些额外指针信息的链表(见算法和数据结构笔记一),借助随机化保能够以少于其他方法的空间保证每一个字典操作都在O(lg n)的期望时间内执行(如insert、delete、search、join、select、rank等操作)
在键都是长字符串时,我们可以构造出比红黑树更灵活而又比散列表更高效的数据结构- Trie树。动机是利用字符串的公共前缀来节约内存,加快检索速度。一般地只要是由关键字集合S中若干元素串在一起的结构叫做Trie,多用于文本串的词频统计,适合前缀匹配和全字匹配
Trie有很多变式,其中一个重要的结构是后缀树,还有后缀树的变形后缀数组。后缀树的单词集合是由指定字符串的后缀子串构成的,适合后缀和子串匹配(常规构造方法或者基于Rabin-Karp算法中的O(nlgn)的 Monto-Carlo算法构造)。它可用于找出字符串S中的最大回文子串S1(如xmadamyx的最长回文子串是madam)、字符串S的最长重复子串S1(如abcdabcefda里abc和da都重复出现,而最长重复子串是abc)、找出字符串S1和S2的最长公共子串(lcs的实现可以基于动态规划或者后缀数组)
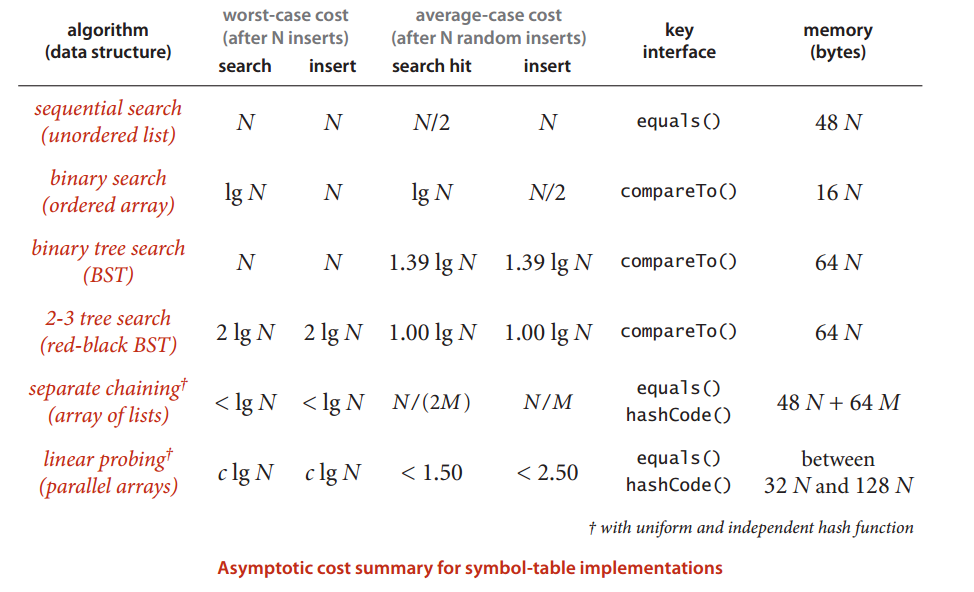
如下图为各种符号表实现的渐进性能的总结: